Del 1: Sette opp en enkelt node
I dag er det både raskt og enkelt å lagre dokumenter eller data på en lagringsenhet, det er også billig. I bruk er en filnavnreferanse som er ment å beskrive hva dokumentet handler om. Alternativt lagres data i et databasestyringssystem (DBMS) som PostgreSQL, MariaDB eller MongoDB for å bare nevne noen alternativer. Flere lagringsmedier er enten lokalt eller eksternt koblet til datamaskinen, for eksempel USB-pinne, intern eller ekstern harddisk, Network Attached Storage (NAS), Cloud Storage eller GPU / Flash-basert, som i en Nvidia V100 [10].
Derimot er den omvendte prosessen, ganske kompleks, å finne de riktige dokumentene i en dokumentsamling. Det krever for det meste å oppdage filformatet uten feil, indeksere dokumentet og trekke ut nøkkelbegrepene (dokumentklassifisering). Dette er hvor Apache Solr-rammen kommer inn. Det tilbyr et praktisk grensesnitt for å utføre trinnene som er nevnt - bygge en dokumentindeks, godta søk, gjøre det faktiske søket og returnere et søkeresultat. Apache Solr danner dermed kjernen for effektiv forskning på en database eller dokumentsilo.
I denne artikkelen vil du lære hvordan Apache Solr fungerer, hvordan du setter opp en enkelt node, indekserer dokumenter, gjør et søk og henter resultatet.
Oppfølgingsartiklene bygger på denne, og i dem diskuterer vi andre, mer spesifikke brukstilfeller som å integrere en PostgreSQL DBMS som datakilde eller belastningsbalansering på tvers av flere noder.
Om Apache Solr-prosjektet
Apache Solr er et søkemotorrammeverk basert på den kraftige Lucene søkeindeksserveren [2]. Skrevet på Java vedlikeholdes den under paraplyen til Apache Software Foundation (ASF) [6]. Den er fritt tilgjengelig under Apache 2-lisensen.
Temaet "Finn dokumenter og data igjen" spiller en veldig viktig rolle i programvareverdenen, og mange utviklere takler det intensivt. Nettstedet Awesomeopensource [4] viser mer enn 150 open source-prosjekter for søkemotorer. Fra begynnelsen av 2021 er ElasticSearch [8] og Apache Solr / Lucene de to beste hundene når det gjelder å søke etter større datasett. Å utvikle søkemotoren din krever mye kunnskap, Frank gjør det med det Python-baserte AdvaS Advanced Search [3] -biblioteket siden 2002.
Sette opp Apache Solr:
Installasjonen og driften av Apache Solr er ikke komplisert, det er ganske enkelt en hel rekke trinn som skal utføres av deg. Tillat omtrent 1 time for resultatet av den første dataspørringen. Videre er Apache Solr ikke bare et hobbyprosjekt, men brukes også i et profesjonelt miljø. Derfor er det valgte operativsystemmiljøet designet for langvarig bruk.
Som basismiljø for denne artikkelen bruker vi Debian GNU / Linux 11, som er den kommende Debian-utgivelsen (fra begynnelsen av 2021) og forventes å være tilgjengelig i midten av 2021. For denne opplæringen forventer vi at du allerede har installert den, enten som det opprinnelige systemet, i en virtuell maskin som VirtualBox, eller en AWS-container.
Bortsett fra de grunnleggende komponentene, trenger du følgende programvarepakker for å være installert på systemet:
- Krølle
- Standard-java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (et bibliotek fra Apache Tika-prosjektet [11])
Disse pakkene er standardkomponenter i Debian GNU / Linux. Hvis det ennå ikke er installert, kan du etterinstallere dem på en gang som en bruker med administrative rettigheter, for eksempel root eller via sudo, vist som følger:
# apt-get install curl default-java libcommons-cli-java libxerces2-java libtika-javaEtter å ha forberedt miljøet, er det andre trinnet installasjonen av Apache Solr. Per nå er ikke Apache Solr tilgjengelig som en vanlig Debian-pakke. Derfor er det nødvendig å hente Apache Solr 8.8 fra nedlastingsdelen av prosjektnettstedet [9] først. Bruk wget-kommandoen nedenfor for å lagre den i / tmp-katalogen på systemet ditt:
$ wget -O / tmp https: // nedlastinger.apache.org / lucene / solr / 8.8.0 / solr-8.8.0.tgzBryteren -O forkorter -output-dokumentet og gjør at wget lagrer den hentede tjæren.gz-filen i den angitte katalogen. Arkivet har en størrelse på omtrent 190M. Deretter pakker du ut arkivet i / opt-katalogen ved hjelp av tjære. Som et resultat finner du to underkataloger - / opt / solr og / opt / solr-8.8.0, mens / opt / solr er satt opp som en symbolsk lenke til sistnevnte. Apache Solr kommer med et installasjonsskript som du utfører neste, det er som følger:
# / opt / solr-8.8.0 / bin / install_solr_service.shDette resulterer i opprettelsen av Linux-bruker solr kjører i Solr-tjenesten pluss hans hjemmekatalog under / var / solr etablerer Solr-tjenesten, lagt til med tilhørende noder, og starter Solr-tjenesten på port 8983. Dette er standardverdiene. Hvis du er misfornøyd med dem, kan du endre dem under installasjonen eller til og med senere siden installasjonsskriptet godtar tilsvarende brytere for oppsettjusteringer. Vi anbefaler deg å ta en titt på Apache Solr-dokumentasjonen angående disse parametrene.
Solr-programvaren er organisert i følgende kataloger:
- søppel
inneholder Solr-binærfiler og filer for å kjøre Solr som en tjeneste - bidrag
eksterne Solr-biblioteker som dataimportbehandler og Lucene-bibliotekene - dist
interne Solr-biblioteker - dokumenter
lenke til Solr-dokumentasjonen tilgjengelig online - eksempel
eksempel datasett eller flere brukssaker / scenarier - lisenser
programvarelisenser for de forskjellige Solr-komponentene - server
serverkonfigurasjonsfiler, for eksempel server / etc for tjenester og porter
Mer detaljert kan du lese om disse katalogene i Apache Solr-dokumentasjonen [12].
Administrere Apache Solr:
Apache Solr kjører som en tjeneste i bakgrunnen. Du kan starte den på to måter, enten ved å bruke systemctl (første linje) som en bruker med administrative tillatelser eller direkte fra Solr-katalogen (andre linje). Vi viser begge terminalkommandoene nedenfor:
# systemctl start solr$ solr / bin / solr start
Stoppe Apache Solr gjøres på samme måte:
# systemctl stopp solr$ solr / søppel / solr stopp
På samme måte går det å starte Apache Solr-tjenesten på nytt:
# systemctl start solr$ solr / bin / solr restart
Videre kan statusen til Apache Solr-prosessen vises som følger:
# systemctl status solr$ solr / bin / solr status
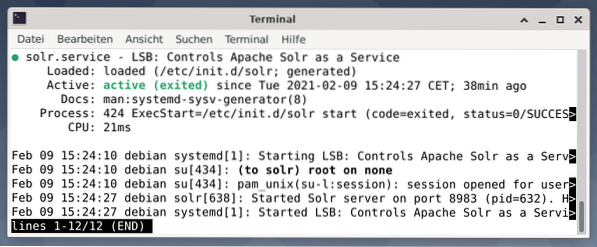
Utgangen viser tjenestefilen som ble startet, både tilhørende tidsstempel og loggmeldinger. Figuren nedenfor viser at Apache Solr-tjenesten ble startet på port 8983 med prosess 632. Prosessen kjører vellykket i 38 minutter.
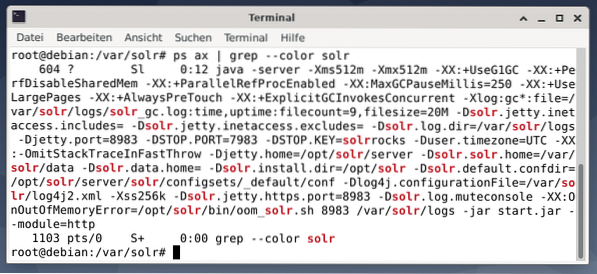
For å se om Apache Solr-prosessen er aktiv, kan du også kryssjekke ved hjelp av ps-kommandoen i kombinasjon med grep. Dette begrenser ps-utgangen til alle Apache Solr-prosessene som er aktive.
# ps øks | grep - farge solrFiguren nedenfor viser dette for en enkelt prosess. Du ser Java-anropet som er ledsaget av en liste over parametere, for eksempel porter for minnebruk (512M) for å lytte på 8983 for spørsmål, 7983 for stoppforespørsler og type tilkobling (http).
Legge til brukere:
Apache Solr-prosessene kjøres med en bestemt bruker som heter solr. Denne brukeren er behjelpelig med å administrere Solr-prosesser, laste opp data og sende forespørsler. Ved oppsett har ikke brukerens passord et passord og forventes å ha et å logge på for å fortsette videre. Sett et passord for brukeren som brukerrot, det vises som følger:
# passwd solrSolr-administrasjon:
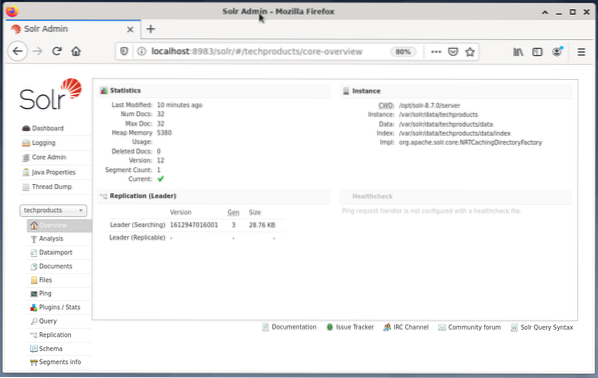
Administrering av Apache Solr gjøres ved hjelp av Solr Dashboard. Dette er tilgjengelig via nettleser fra http: // localhost: 8983 / solr. Figuren nedenfor viser hovedvisningen.
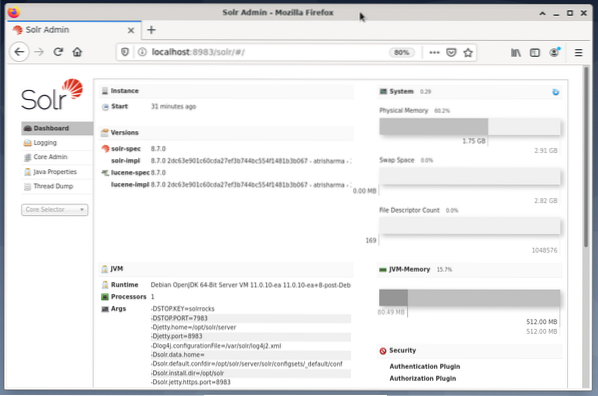
Til venstre ser du hovedmenyen som fører deg til underseksjonene for logging, administrasjon av Solr-kjernene, Java-oppsettet og statusinformasjonen. Velg ønsket kjerne ved hjelp av valgboksen under menyen. På høyre side av menyen vises tilsvarende informasjon. Dashboard-menyoppføringen viser ytterligere detaljer om Apache Solr-prosessen, samt gjeldende belastning og minnebruk.
Vær oppmerksom på at innholdet på dashbordet endres avhengig av antall Solr-kjerner og dokumentene som er indeksert. Endringer påvirker både menyelementene og den tilsvarende informasjonen som er synlig til høyre.
Forstå hvordan søkemotorer fungerer:
Enkelt sagt, søkemotorer analyserer dokumenter, kategoriserer dem og lar deg gjøre et søk basert på kategoriseringen. I utgangspunktet består prosessen av tre trinn, som betegnes som gjennomsøking, indeksering og rangering [13].
Krabbe er den første fasen og beskriver en prosess der nytt og oppdatert innhold blir samlet inn. Søkemotoren bruker roboter som også er kjent som edderkopper eller crawlere, derav begrepet crawling for å gå gjennom tilgjengelige dokumenter.
Den andre fasen heter indeksering. Det tidligere innsamlede innholdet gjøres søkbart ved å transformere originaldokumentene til et format søkemotoren forstår. Nøkkelord og konsepter hentes ut og lagres i (massive) databaser.
Den tredje fasen heter rangering og beskriver prosessen med å sortere søkeresultatene etter deres relevans med et søk. Det er vanlig å vise resultatene i synkende rekkefølge, slik at resultatet som har størst relevans for søkerens søk kommer først.
Apache Solr fungerer på samme måte som den tidligere beskrevne tretrinnsprosessen. I likhet med den populære søkemotoren Google bruker Apache Solr en sekvens med å samle, lagre og indeksere dokumenter fra forskjellige kilder og gjør dem tilgjengelige / søkbare i nær sanntid.
Apache Solr bruker forskjellige måter å indeksere dokumenter, inkludert følgende [14]:
- Bruke en indeksforespørselsbehandler når du laster opp dokumentene direkte til Solr. Disse dokumentene skal være i JSON-, XML / XSLT- eller CSV-format.
- Bruke Extracting Request Handler (Solr Cell). Dokumentene skal være i PDF- eller Office-format, som støttes av Apache Tika.
- Ved hjelp av Data Import Handler, som formidler data fra en database og katalogiserer dem ved hjelp av kolonnenavn. Data Import Handler henter data fra e-post, RSS-feeder, XML-data, databaser og ren tekstfiler som kilder.
En spørringshåndterer brukes i Apache Solr når en søkeforespørsel blir sendt. Spørrehåndtereren analyserer den gitte spørringen basert på samme konsept som indekshåndtereren for å matche spørringen og tidligere indekserte dokumenter. Kampene rangeres etter hensiktsmessighet eller relevans. Et kort eksempel på spørring er demonstrert nedenfor.
Laste opp dokumenter:
For enkelhets skyld bruker vi et eksemplerdatasett for følgende eksempel som allerede er levert av Apache Solr. Opplasting av dokumenter gjøres som brukeren. Trinn 1 er opprettelsen av en kjerne med navnet techproducts (for en rekke tech items).
$ solr / bin / solr create -c techproducts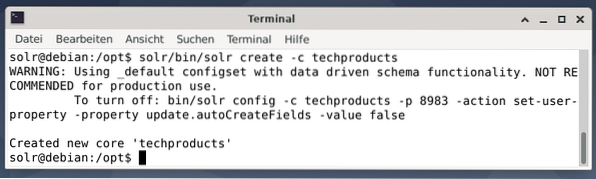
Alt er bra hvis du ser meldingen "Skapt ny kjerne" techproducts "". Trinn 2 er å legge til data (XML-data fra exampledocs) til de tidligere opprettede kjernetekniske produktene. I bruk er verktøyposten som er parameterisert med -c (navnet på kjernen) og dokumentene som skal lastes opp.
$ solr / bin / post -c techproducts solr / eksempel / exampledocs / *.xmlDette vil resultere i utdataene vist nedenfor og vil inneholde hele samtalen pluss de 14 dokumentene som er indeksert.
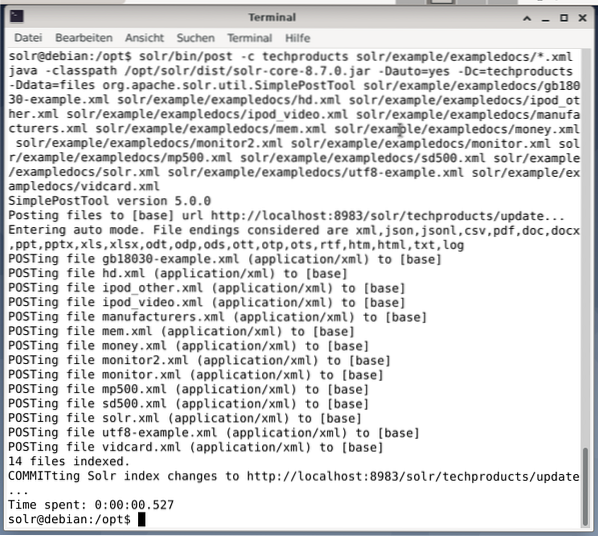
Dashboard viser også endringene. En ny oppføring med navnet techproducts er synlig i rullegardinmenyen på venstre side, og antall tilsvarende dokumenter endret på høyre side. Dessverre er en detaljert oversikt over de rå datasettene ikke mulig.
Hvis kjernen / samlingen må fjernes, bruk følgende kommando:
$ solr / bin / solr delete -c techproductsSpørringsdata:
Apache Solr tilbyr to grensesnitt for spørringsdata: via det nettbaserte dashbordet og kommandolinjen. Vi vil forklare begge metodene nedenfor.
Sende spørsmål via Solr dashbord gjøres som følger:
- Velg noden techproducts fra rullegardinmenyen.
- Velg oppføringen Spørring fra menyen under rullegardinmenyen.
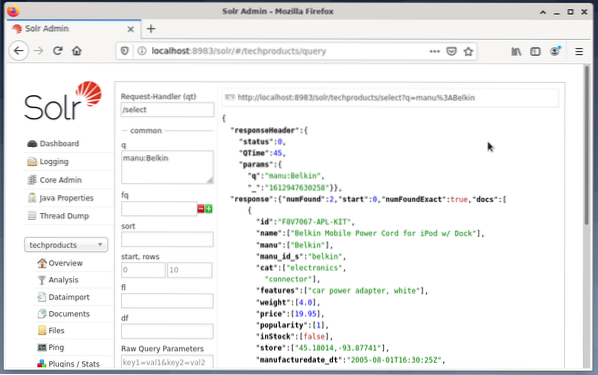
Inntastingsfelt dukker opp på høyre side for å formulere spørringen som forespørselsbehandler (qt), spørring (q) og sorteringsrekkefølgen (sortering). - Velg oppføringsfeltet Spørring, og endre innholdet i oppføringen fra “*: *” til “manu: Belkin”. Dette begrenser søket fra "alle felt med alle oppføringer" til "datasett som har navnet Belkin i manufeltet". I dette tilfellet forkorter navnet manu produsenten i eksemplet datasettet.
- Trykk deretter på knappen med Utfør spørring. Resultatet er en utskrevet HTTP-forespørsel på toppen, og et resultat av søket i JSON-dataformat nedenfor.
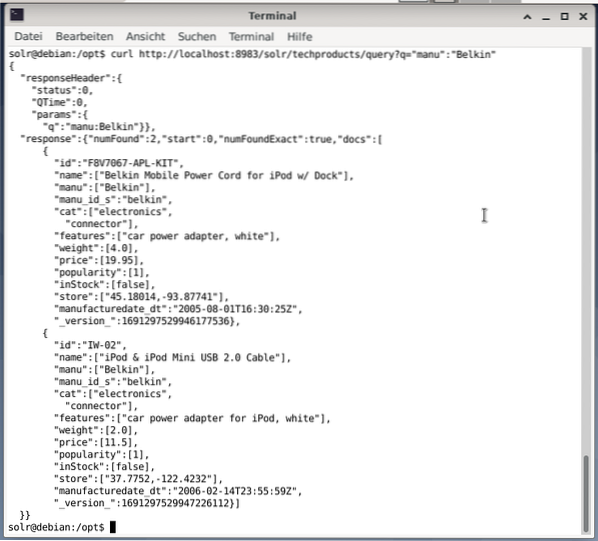
Kommandolinjen godtar den samme spørringen som i dashbordet. Forskjellen er at du må vite navnet på søkefeltene. For å sende den samme spørringen som ovenfor, må du kjøre følgende kommando i en terminal:
$ krøllhttp: // localhost: 8983 / solr / techproducts / spørring?q = ”manu”: ”Belkin
Utgangen er i JSON-format, som vist nedenfor. Resultatet består av en svarhode og den faktiske responsen. Svaret består av to datasett.
Innpakning:
Gratulerer! Du har oppnådd den første fasen med suksess. Den grunnleggende infrastrukturen er satt opp, og du har lært å laste opp og spørre dokumenter.
Neste trinn vil dekke hvordan du kan finjustere spørringen, formulere mer komplekse spørsmål og forstå de forskjellige webskjemaene som tilbys fra Apache Solr-spørringssiden. Vi vil også diskutere hvordan du kan behandle søkeresultatet etter forskjellige utdataformater som XML, CSV og JSON.
Om forfatterne:
Jacqui Kabeta er miljøverner, ivrig forsker, trener og mentor. I flere afrikanske land har hun jobbet i IT-bransjen og NGO-miljøer.
Frank Hofmann er IT-utvikler, trener og forfatter og foretrekker å jobbe fra Berlin, Genève og Cape Town. Medforfatter av Debian Package Management Book tilgjengelig fra dpmb.org
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Lucene Search Library, https: // lucene.apache.org /
- [3] AdvaS Advanced Search, https: // pypi.org / prosjekt / AdvaS-Advanced-Search /
- [4] Topp 165-søkemotorens åpen kildekode-prosjekter, https: // awesomeopensource.com / prosjekter / søkemotor
- [5] ElasticSearch, https: // www.elastisk.co / de / elasticsearch /
- [6] Apache Software Foundation (ASF), https: // www.apache.org /
- [7] FESS, https: // fess.codelibs.org / indeks.html
- [8] ElasticSearch, https: // www.elastisk.kode/
- [9] Apache Solr, nedlastingsseksjon, https: // lucene.apache.org / solr / nedlastinger.htm
- [10] Nvidia V100, https: // www.nvidia.no / no-us / datasenter / v100 /
- [11] Apache Tika, https: // tika.apache.org /
- [12] Apache Solr katalogoppsett, https: // lucene.apache.org / solr / guide / 8_8 / installasjon-solr.html # katalogoppsett
- [13] Hvordan søkemotorer fungerer: gjennomsøking, indeksering og rangering. Nybegynnerguiden for SEO https: // moz.no / nybegynner-guide-til-seo / hvordan-søkemotorer fungerer
- [14] Kom i gang med Apache Solr, https: // sematekst.com / guides / solr / #: ~: text = Solr% 20works% 20by% 20gathering% 2C% 20storing, med% 20huge% 20volumes% 20of% 20data


