Hvis du for eksempel vil få regelmessige oppdateringer om favorittproduktene dine for rabatttilbud, eller hvis du vil automatisere prosessen med å laste ned episoder av favorittsesongen din en etter en, og nettstedet ikke har noen API for det, så er det eneste valget du sitter igjen med er nettskraping.Nettskraping kan være ulovlig på noen nettsteder, avhengig av om et nettsted tillater det eller ikke. Nettsteder bruker “roboter.txt ”-fil for å eksplisitt definere URL-er som ikke er tillatt å bli utrangert. Du kan sjekke om nettstedet tillater det eller ikke ved å legge til “roboter.txt ”med nettstedets domenenavn. For eksempel https: // www.Google.com / roboter.tekst
I denne artikkelen bruker vi Python til skraping fordi det er veldig enkelt å installere og bruke. Den har mange innebygde og tredjeparts bibliotekar som kan brukes til å skrape og organisere data. Vi bruker to Python-biblioteker "urllib" for å hente websiden og "BeautifulSoup" for å analysere nettsiden for å bruke programmeringsoperasjoner.
Hvordan fungerer Web Scraping?
Vi sender en forespørsel til websiden, hvorfra du vil skrape dataene. Nettstedet vil svare på forespørselen med HTML-innhold på siden. Deretter kan vi analysere denne nettsiden til BeautifulSoup for videre behandling. For å hente websiden bruker vi biblioteket “urllib” i Python.
Urllib vil laste ned innholdet på websiden i HTML. Vi kan ikke bruke strengoperasjoner på denne HTML-nettsiden for innholdsutvinning og viderebehandling. Vi bruker et Python-bibliotek "BeautifulSoup" som vil analysere innholdet og trekke ut interessante data.
Skraping av artikler fra Linuxhint.com
Nå som vi har en idé om hvordan nettskraping fungerer, la oss gjøre litt øvelse. Vi prøver å skrape artikkeltitler og lenker fra Linuxhint.com. Så åpne https: // linuxhint.com / i nettleseren din.
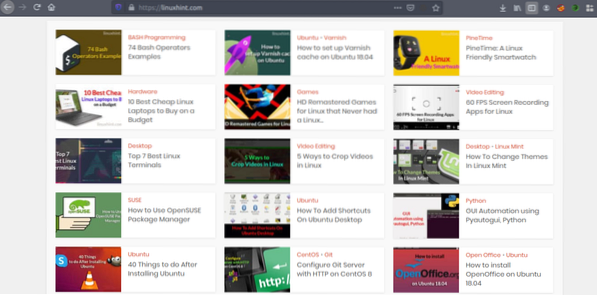
Trykk nå CRTL + U for å vise HTML-kildekoden til websiden.
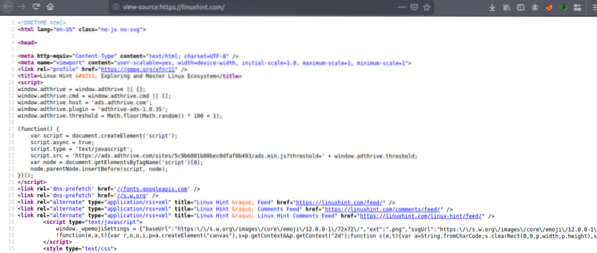
Kopier kildekoden, og gå til https: // htmlformatter.com / for å angi koden. Etter å ha prettifisert koden, er det enkelt å inspisere koden og finne interessant informasjon.
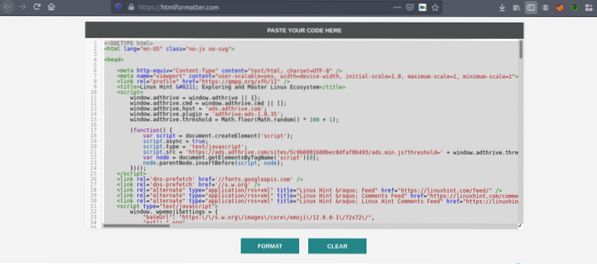
Nå, kopier igjen den formaterte koden og lim den inn i din favoritt tekstredigerer som atom, sublim tekst osv. Nå skraper vi interessant informasjon ved hjelp av Python. Skriv inn følgende
// Installer vakkert suppebibliotek, kommer urllibforhåndsinstallert i Python
ubuntu @ ubuntu: ~ $ sudo pip3 installer bs4
ubuntu @ ubuntu: ~ $ python3
Python 3.7.3 (standard, 7. okt 2019, 12:56:13)
[GCC 8.3.0] på linux
Skriv inn “help”, “copyright”, “credits” eller “lisens” for mer informasjon.
// Importer urllib>>> import urllib.be om
// Importer BeautifulSoup
>>> fra bs4 import BeautifulSoup
// Skriv inn URL-en du vil hente
>>> my_url = 'https: // linuxhint.com / '
// Be om URL-nettsiden ved hjelp av urlopen-kommandoen
>>> klient = urllib.be om.urlopen (min_url)
// Lagre HTML-websiden i “html_page” -variabelen
>>> html_page = klient.lese()
// Lukk URL-tilkoblingen etter henting av websiden
>>> klient.Lukk()
// analyser HTML-websiden til BeautifulSoup for skraping
>>> page_soup = BeautifulSoup (html_page, "html.parser ")
La oss nå se på HTML-kildekoden vi nettopp kopierte og limte inn for å finne ting av interesse.
Du kan se at den første artikkelen er oppført på Linuxhint.com heter "74 Bash Operators Eksempler", finn dette i kildekoden. Den er lukket mellom topptekstene, og koden er
title = "74 Bash Operators Eksempler"> 74 Bash Operators
Eksempler
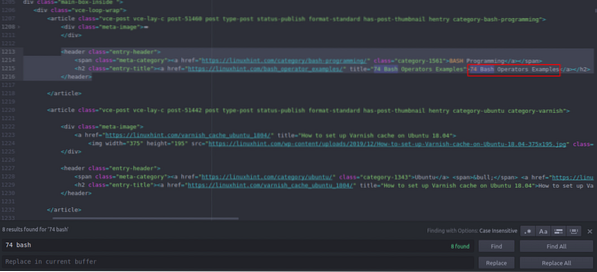
Den samme koden gjentas om og om igjen med endring av bare artikkeltitler og lenker. Neste artikkel har følgende HTML-kode
title = "Hvordan sette opp Varnish cache på Ubuntu 18.04 ">
Slik setter du opp Varnish-cache på Ubuntu 18.04
Du kan se at alle artiklene, inkludert disse to, er lukket i samme “
”Tag og bruk samme klasse“ entry-title ”. Vi kan bruke "findAll" -funksjonen i Beautiful Soup-biblioteket for å finne og liste opp alle "”Har klasse“ entry-title ”. Skriv inn følgende i Python-konsollen // Denne kommandoen finner alle “”Taggelementer med klasse oppkalt
“Entry-title”. Utdataene lagres i en matrise.
>>> artikler = sidesuppe.findAll ("h2" ,
"class": "entry-title")
// Antall artikler funnet på forsiden av Linuxhint.com
>>> len (artikler)
102
// Først hentet “”Taggelement som inneholder artikkelnavn og lenke
>>> artikler [0]
title = "74 Bash Operators Eksempler">
74 Eksempler på Bash Operators
// Andre ekstrahert “”Taggelement som inneholder artikkelnavn og lenke
>>> artikler [1]
title = "Hvordan sette opp Varnish cache på Ubuntu 18.04 ">
Slik setter du opp Varnish-cache på Ubuntu 18.04
// Viser bare tekst i HTML-koder ved hjelp av tekstfunksjon
>>> artikler [1].tekst
'Hvordan sette opp Varnish-cache på Ubuntu 18.04 '
”Taggelementer med klasse oppkalt
“Entry-title”. Utdataene lagres i en matrise.
>>> artikler = sidesuppe.findAll ("h2" ,
"class": "entry-title")
// Antall artikler funnet på forsiden av Linuxhint.com
>>> len (artikler)
102
// Først hentet “”Taggelement som inneholder artikkelnavn og lenke
>>> artikler [0]
title = "74 Bash Operators Eksempler">
74 Eksempler på Bash Operators
// Andre ekstrahert “”Taggelement som inneholder artikkelnavn og lenke
>>> artikler [1]
title = "Hvordan sette opp Varnish cache på Ubuntu 18.04 ">
Slik setter du opp Varnish-cache på Ubuntu 18.04
// Viser bare tekst i HTML-koder ved hjelp av tekstfunksjon
>>> artikler [1].tekst
'Hvordan sette opp Varnish-cache på Ubuntu 18.04 '
>>> artikler [0]
title = "74 Bash Operators Eksempler">
74 Eksempler på Bash Operators
// Andre ekstrahert “
”Taggelement som inneholder artikkelnavn og lenke
>>> artikler [1]
title = "Hvordan sette opp Varnish cache på Ubuntu 18.04 ">
Slik setter du opp Varnish-cache på Ubuntu 18.04
// Viser bare tekst i HTML-koder ved hjelp av tekstfunksjon
>>> artikler [1].tekst
'Hvordan sette opp Varnish-cache på Ubuntu 18.04 '
title = "Hvordan sette opp Varnish cache på Ubuntu 18.04 ">
Slik setter du opp Varnish-cache på Ubuntu 18.04
Nå som vi har en liste over alle 102 HTML “
”Taggelementer som inneholder artikkelkobling og artikkeltittel. Vi kan trekke ut både artiklelink og titler. For å trekke ut lenker fra “”-Koder, kan vi bruke følgende kode // Følgende kode vil trekke ut lenken fra først merkeelement
>>> for lenke i artikler [0].find_all ('a', href = True):
... skriv ut (lenke ['href'])
..
https: // linuxhint.com / bash_operator_examples /
Nå kan vi skrive en for-løkke som går gjennom hver “
”Taggelement i” artikler ”-listen og trekk ut artikkelkoblingen og tittelen. >>> for i innen rekkevidde (0,10):
... skriv ut (artikler [i].tekst)
... for lenke i artikler [i].find_all ('a', href = True):
... skriv ut (lenke ['href'] + "\ n")
..
74 Eksempler på Bash Operators
https: // linuxhint.com / bash_operator_examples /
Slik setter du opp Varnish-cache på Ubuntu 18.04
https: // linuxhint.no / varnish_cache_ubuntu_1804 /
PineTime: En Linux-vennlig smartklokke
https: // linuxhint.no / pinetime_linux_smartwatch /
10 beste billige Linux-bærbare datamaskiner å kjøpe på et budsjett
https: // linuxhint.no / best_cheap_linux_laptops /
HD Remastered Games for Linux som aldri hadde en Linux-utgivelse ..
https: // linuxhint.no / hd_remastered_games_linux /
60 FPS-skjermopptaksprogrammer for Linux
https: // linuxhint.no / 60_fps_screen_recording_apps_linux /
74 Eksempler på Bash Operators
https: // linuxhint.com / bash_operator_examples /
... snip ..
På samme måte lagrer du disse resultatene i en JSON- eller CSV-fil.
Konklusjon
De daglige oppgavene dine er ikke bare filadministrasjon eller systemutførelse. Du kan også automatisere nettrelaterte oppgaver som automatisering av filnedlasting eller datautvinning ved å skrape nettet i Python. Denne artikkelen var begrenset til bare enkel datautvinning, men du kan gjøre enorm oppgaveautomatisering ved hjelp av "urllib" og "BeautifulSoup".
>>> for lenke i artikler [0].find_all ('a', href = True):
... skriv ut (lenke ['href'])
..
https: // linuxhint.com / bash_operator_examples /
... skriv ut (artikler [i].tekst)
... for lenke i artikler [i].find_all ('a', href = True):
... skriv ut (lenke ['href'] + "\ n")
..
74 Eksempler på Bash Operators
https: // linuxhint.com / bash_operator_examples /
Slik setter du opp Varnish-cache på Ubuntu 18.04
https: // linuxhint.no / varnish_cache_ubuntu_1804 /
PineTime: En Linux-vennlig smartklokke
https: // linuxhint.no / pinetime_linux_smartwatch /
10 beste billige Linux-bærbare datamaskiner å kjøpe på et budsjett
https: // linuxhint.no / best_cheap_linux_laptops /
HD Remastered Games for Linux som aldri hadde en Linux-utgivelse ..
https: // linuxhint.no / hd_remastered_games_linux /
60 FPS-skjermopptaksprogrammer for Linux
https: // linuxhint.no / 60_fps_screen_recording_apps_linux /
74 Eksempler på Bash Operators
https: // linuxhint.com / bash_operator_examples /
... snip ..


