Gjennom databehandling og analyse støtter histogrammer deg til å representere frekvensfordeling og få innsikt enkelt. Vi vil se på noen få forskjellige metoder for å oppnå frekvensfordeling i PostgreSQL. For å bygge et histogram i PostgreSQL, kan du bruke en rekke PostgreSQL Histogram-kommandoer. Vi vil forklare hver enkelt for seg.
Først må du sørge for at du har PostgreSQL kommandolinjeskall og pgAdmin4 installert i datamaskinsystemet. Åpne nå PostgreSQL-kommandolinjeskallet for å begynne å jobbe med histogrammer. Det vil umiddelbart be deg om å angi servernavnet du vil jobbe med. Som standard er 'localhost'-serveren valgt. Hvis du ikke angir en mens du hopper til neste alternativ, fortsetter den med standard. Etter det vil det be deg om å oppgi databasenavn, portnummer og brukernavn å jobbe med. Hvis du ikke oppgir en, fortsetter den med standard. Som du kan se fra bildet vedlagt nedenfor, vil vi jobbe med testdatabasen. Endelig skriver du inn passordet for den aktuelle brukeren og gjør deg klar.
Eksempel 01:
Vi må ha noen tabeller og data i databasen vår å jobbe med. Så vi har laget et tabell "produkt" i databasen "test" for å lagre postene for forskjellige produktsalg. Denne tabellen har to kolonner. Den ene er 'order_date' for å lagre datoen da bestillingen er gjort, og den andre er 'p_sold' for å lagre det totale antallet salg på en bestemt dato. Prøv spørringen nedenfor i kommandoskallet for å lage denne tabellen.
>> OPPRETT TABELL produkt (ordredato DATO, p_sold INT);
Akkurat nå er tabellen tom, så vi må legge til noen poster i den. Så prøv INSERT-kommandoen nedenfor i skallet for å gjøre det.
>> INSERT I PRODUKTVERDIER ('2021-03-01', 1250), ('2021-04-02', 555), ('2021-06-03', 500), ('2021-05-04' , 1000), ('2021-10-05', 890), ('2021-12-10', 1000), ('2021-01-06', 345), ('2021-11-07', 467 ), ('2021-02-08', 1250), ('2021-07-09', 789);
Nå kan du sjekke at tabellen har data i den ved hjelp av SELECT-kommandoen som sitert nedenfor.
>> VELG * FRA produktet;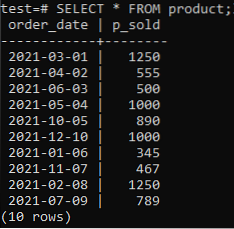
Bruk av gulv og søppel:
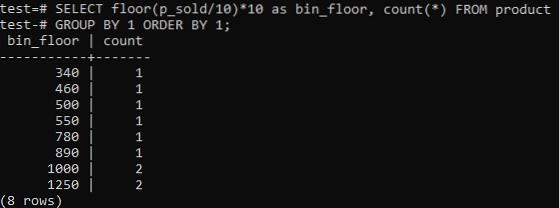
Hvis du liker PostgreSQL Histogram-søppelbøtter for å gi lignende perioder (10-20, 20-30, 30-40, osv.), kjør SQL-kommandoen nedenfor. Vi estimerer bingenummeret fra utsagnet nedenfor ved å dele salgsverdien med en histogrambakkestørrelse, 10.
Denne tilnærmingen har fordelen av å endre søppelkassene dynamisk når data legges til, slettes eller endres. Det legger også til ekstra kasser for nye data og / eller sletter kasser hvis antallet deres når null. Som et resultat kan du generere histogrammer effektivt i PostgreSQL.
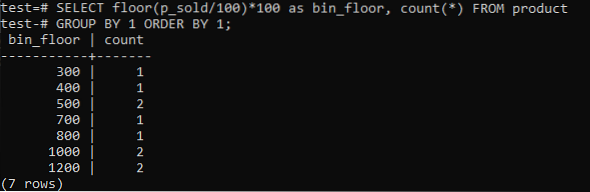
Skifte gulv (p_sold / 10) * 10 med gulv (p_sold / 100) * 100 for å øke søppelstørrelsen til 100.
Bruke WHERE-klausul:
Du vil konstruere en frekvensfordeling ved bruk av CASE-erklæring mens du forstår histogrambøttene som skal genereres, eller hvordan histogrambeholderstørrelsene varierer. For PostgreSQL er nedenfor en annen Histogram-uttalelse:
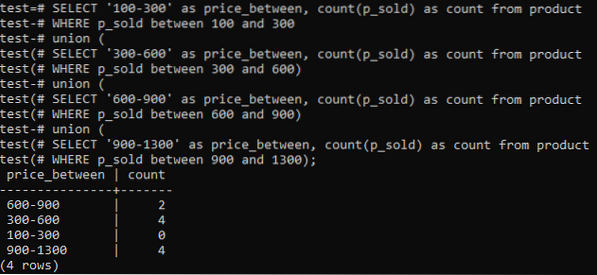
>> VELG '100-300' AS pris mellom, COUNT (p_sold) AS COUNT FROM product WHERE p_sold MELLOM 100 AND 300 UNION (VELG '300-600' AS price_between, COUNT (p_sold) AS COUNT FROM product WHERE p_sold MELLOM 300 AND 600 ) UNION (VELG '600-900' AS pris_ mellom, COUNT (p_sold) AS COUNT FROM product WHERE p_sold MELLOM 600 AND 900) UNION (SELECT '900-1300' AS price_between, COUNT (p_sold) AS COUNT FROM product WHERE p_sold MELLAN 900 OG 1300);Og utgangen viser distribusjonen av histogramfrekvensen for de totale verdiene for kolonnen 'p_sold' og tellingsnummeret. Prisene varierer fra 300-600 og 900-1300 har en totalantall på 4 hver for seg. Salgsområdet på 600-900 fikk 2 teller mens området 100-300 fikk 0 teller salg.
Eksempel 02:
La oss vurdere et annet eksempel for å illustrere histogrammer i PostgreSQL. Vi har laget en tabell 'student' ved å bruke kommandoen sitert nedenfor i skallet. Denne tabellen lagrer informasjonen om studenter og antall mislykkede tall de har.
>> OPPRETT TABELL-student (std_id INT, fail_count INT);
Tabellen må ha noen data i seg. Så vi har utført INSERT INTO-kommandoen for å legge til data i tabellen 'student' som:
>> INNFØR studentverdier (111, 30), (112, 60), (113, 90), (114, 3), (115, 120), (116, 150), (117, 180), (118 , 210), (119, 5), (120, 300), (121, 380), (122, 470), (123, 530), (124, 9), (125, 550), (126, 50 ), (127, 40), (128, 8);
Nå er tabellen fylt med en enorm mengde data i henhold til utdataene som vises. Den har tilfeldige verdier for std_id og fail_count av studenter.
>> VELG * FRA studenten;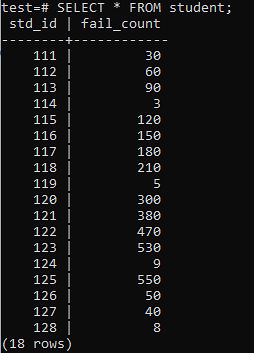
Når du prøver å kjøre et enkelt spørsmål for å samle det totale antallet feil som en student har, så vil du ha nedenstående utdata. Utdataene viser bare det separate antallet mislykkede tellinger for hver elev en gang fra 'count' -metoden som brukes i kolonnen 'std_id'. Dette ser ikke veldig tilfredsstillende ut.
>> VELG fail_count, COUNT (std_id) FRA student GRUPPE MED 1 BESTILLING AV 1;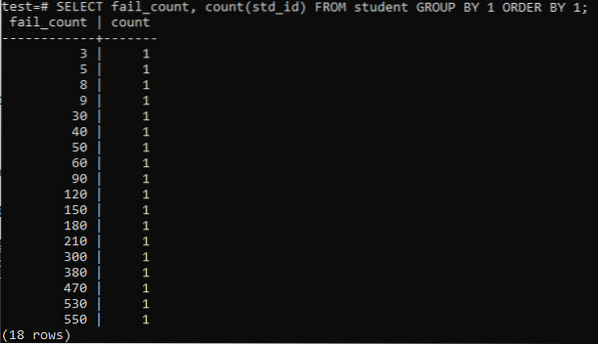
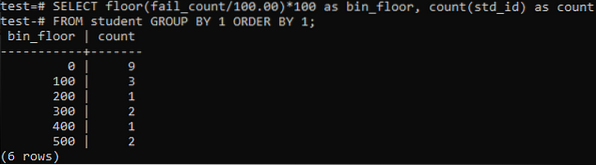
Vi vil bruke gulvmetoden igjen i dette tilfellet i lignende perioder eller intervaller. Så utfør spørringen nedenfor i kommandoskallet. Spørringen deler studentenes 'fail_count' med 100.00 og bruker deretter gulvfunksjonen for å lage en søppel i størrelse 100. Deretter oppsummeres det totale antallet studenter som bor i dette bestemte området.
Konklusjon:
Vi kan generere et histogram med PostgreSQL ved hjelp av noen av teknikkene som er nevnt tidligere, avhengig av kravene. Du kan endre histogrambøttene til hvert utvalg du ønsker; ensartede intervaller er ikke nødvendig. Gjennom denne opplæringen prøvde vi å forklare de beste eksemplene for å fjerne konseptet ditt om histogramoppretting i PostgreSQL. Jeg håper, ved å følge noen av disse eksemplene, kan du enkelt lage et histogram for dataene dine i PostgreSQL.


