For eksempel kan en bedrift kjøre en tekstanalysemotor som behandler tweets om virksomheten og nevner firmanavn, plassering, prosess og analyserer følelser relatert til den tweeten. Korrekte tiltak kan iverksettes raskere hvis den virksomheten blir kjent med økende negative tweets for den på et bestemt sted for å redde seg fra en bommert eller noe annet. Et annet vanlig eksempel vil for Youtube. Youtube-administratorer og moderatorer blir kjent med effekten av en video, avhengig av typen kommentarer som blir gjort på en video eller videochatmeldingene. Dette vil hjelpe dem med å finne upassende innhold på nettstedet mye raskere, for nå har de utryddet manuelt arbeid og ansatt automatiserte smarte tekstanalysebots.
I denne leksjonen vil vi studere noen av konseptene knyttet til tekstanalyse ved hjelp av NLTK-biblioteket i Python. Noen av disse konseptene vil involvere:
- Tokenisering, hvordan dele en tekst i ord, setninger
- Unngå stoppord basert på engelsk
- Utføre stemming og lemmatisering på et stykke tekst
- Identifisere tokens som skal analyseres
NLP vil være hovedfokusområdet i denne leksjonen, da det kan brukes i enorme virkelige scenarier der det kan løse store og avgjørende problemer. Hvis du synes dette høres komplekst ut, gjør det det, men begrepene er like enkle å forstå hvis du prøver eksempler ved siden av hverandre. La oss hoppe inn i å installere NLTK på maskinen din for å komme i gang med det.
Installerer NLTK
Bare et notat før du starter, kan du bruke et virtuelt miljø for denne leksjonen som vi kan lage med følgende kommando:
python -m virtualenv nltkkilde nltk / bin / aktiver
Når det virtuelle miljøet er aktivt, kan du installere NLTK-biblioteket i det virtuelle miljøet slik at eksempler vi oppretter neste kan utføres:
pip install nltkVi vil bruke Anaconda og Jupyter i denne leksjonen. Hvis du vil installere den på maskinen din, kan du se på leksjonen som beskriver “Slik installerer du Anaconda Python på Ubuntu 18.04 LTS ”og del din tilbakemelding hvis du har problemer. For å installere NLTK med Anaconda, bruk følgende kommando i terminalen fra Anaconda:
conda install-c anaconda nltkVi ser noe slikt når vi utfører kommandoen ovenfor:
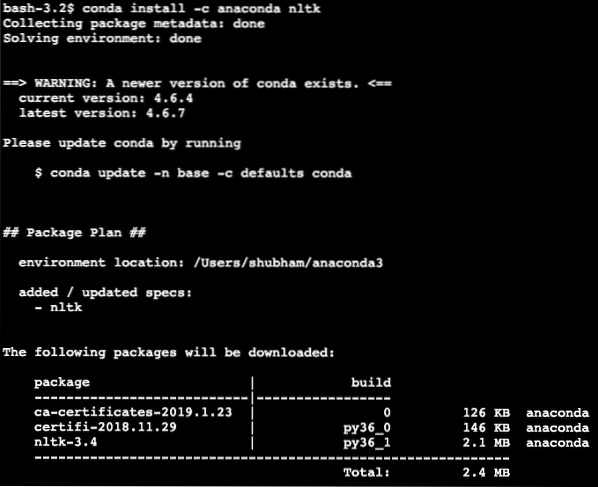
Når alle nødvendige pakker er installert og ferdig, kan vi komme i gang med å bruke NLTK-biblioteket med følgende importuttalelse:
importer nltkLa oss komme i gang med grunnleggende NLTK-eksempler nå som forutsetningspakkene er installert.
Tokenisering
Vi starter med tokenisering som er det første trinnet i å utføre tekstanalyse. Et token kan være en hvilken som helst mindre del av et stykke tekst som kan analyseres. Det er to typer tokeniseringer som kan utføres med NLTK:
- Setningstokenisering
- Word Tokenization
Du kan gjette hva som skjer på hver av tokeniseringen, så la oss dykke ned i kodeeksempler.
Setningstokenisering
Som navnet gjenspeiler, deler Sentence Tokenizers et stykke tekst i setninger. La oss prøve en enkel kodebit for det samme der vi bruker en tekst vi valgte fra Apache Kafka tutorial. Vi vil utføre den nødvendige importen
importer nltkfra nltk.tokenize import sent_tokenize
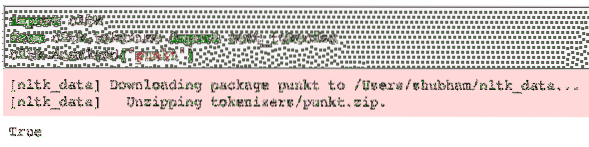
Vær oppmerksom på at det kan oppstå en feil på grunn av manglende avhengighet av nltk punkt. Legg til følgende linje rett etter importen i programmet for å unngå advarsler:
nltk.last ned ('punkt')For meg ga det følgende resultat:
Deretter bruker vi setningen tokenizer vi importerte:
text = "" "Et emne i Kafka er noe der det sendes en melding. Forbrukerenapplikasjoner som er interessert i dette emnet trekker meldingen inn i det
emne og kan gjøre hva som helst med disse dataene. Opp til et bestemt tidspunkt, et hvilket som helst antall
forbrukerapplikasjoner kan trekke denne meldingen et antall ganger."" "
setninger = sent_tokenize (tekst)
skriv ut (setninger)
Vi ser noe slikt når vi utfører skriptet ovenfor:

Som forventet var teksten ordnet ordentlig i setninger.
Word Tokenization
Som navnet gjenspeiler, bryter Word Tokenizers et stykke tekst i ord. La oss prøve et enkelt kodebit for det samme med samme tekst som forrige eksempel:
fra nltk.tokenize import word_tokenizeord = ord_tokenize (tekst)
skrive ut (ord)
Vi ser noe slikt når vi utfører skriptet ovenfor:

Som forventet var teksten ordnet ordentlig.
Frekvensfordeling
Nå som vi har brutt teksten, kan vi også beregne hyppigheten av hvert ord i teksten vi brukte. Det er veldig enkelt å gjøre med NLTK, her er kodebiten vi bruker:
fra nltk.sannsynlighetsimport FreqDistdistribusjon = FreqDist (ord)
trykk (distribusjon)
Vi ser noe slikt når vi utfører skriptet ovenfor:

Deretter kan vi finne de vanligste ordene i teksten med en enkel funksjon som godtar antall ord som skal vises:
# Mest vanlige ordfordeling.vanligste (2)
Vi ser noe slikt når vi utfører skriptet ovenfor:

Til slutt kan vi lage et frekvensfordelingsdiagram for å fjerne ordene og antallet deres i den gitte teksten og tydelig forstå fordelingen av ord:

Stoppord
Akkurat som når vi snakker med en annen person via en samtale, har det en tendens til å være noe støy over samtalen som er uønsket informasjon. På samme måte inneholder tekst fra den virkelige verden også støy som kalles Stoppord. Stoppord kan variere fra språk til språk, men de kan lett identifiseres. Noen av stoppordene på engelsk kan være - er, er, en, den, et osv.
Vi kan se på ord som anses som stoppord av NLTK for engelsk med følgende kodebit:
fra nltk.stoppord for corpusimportnltk.last ned ('stoppord')
språk = "engelsk"
stop_words = sett (stoppord.ord (språk))
skriv ut (stoppord)
Ettersom stoppordet selvfølgelig kan være stort, lagres det som et eget datasett som kan lastes ned med NLTK som vist ovenfor. Vi ser noe slikt når vi utfører skriptet ovenfor:
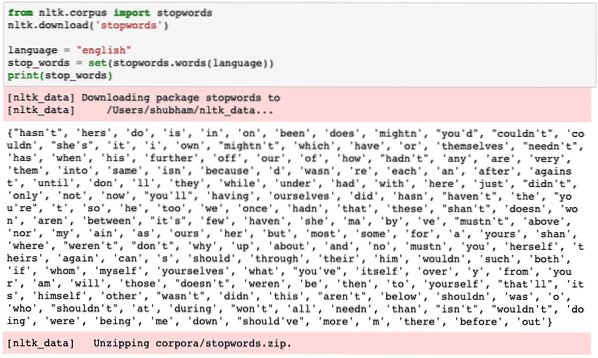
Disse stoppordene bør fjernes fra teksten hvis du vil utføre en presis tekstanalyse for teksten. La oss fjerne stoppordene fra teksttegnene våre:
filtered_words = []for ord i ord:
hvis ord ikke er i stoppord:
filtrerte_ord.legge til (ord)
filtrerte_ord
Vi ser noe slikt når vi utfører skriptet ovenfor:

Word Stemming
En stamme av et ord er grunnlaget for det ordet. For eksempel:
Vi vil utføre stammer fra de filtrerte ordene som vi fjernet stoppord fra i den siste delen. La oss skrive et enkelt kodebit der vi bruker NLTKs stemmer for å utføre operasjonen:
fra nltk.stammeimport PorterStemmerps = PorterStemmer ()
stemmed_words = []
for ord i filtrerte_ord:
stemmed_words.legge til (ps.stamme (ord))
utskrift ("Stemmed Setning:", stemmed_words)
Vi ser noe slikt når vi utfører skriptet ovenfor:

POS-merking
Neste trinn i tekstanalyse er etter stemming å identifisere og gruppere hvert ord i form av deres verdi, dvs.e. hvis hvert av ordene er et substantiv eller et verb eller noe annet. Dette betegnes som en del av talemerking. La oss utføre POS-merking nå:
tokens = nltk.word_tokenize (setninger [0])print (tokens)
Vi ser noe slikt når vi utfører skriptet ovenfor:

Nå kan vi utføre merkingen, som vi må laste ned et annet datasett for å identifisere de riktige kodene:
nltk.nedlasting ('averaged_perceptron_tagger')nltk.pos_tag (tokens)
Her er utdataene fra merkingen:
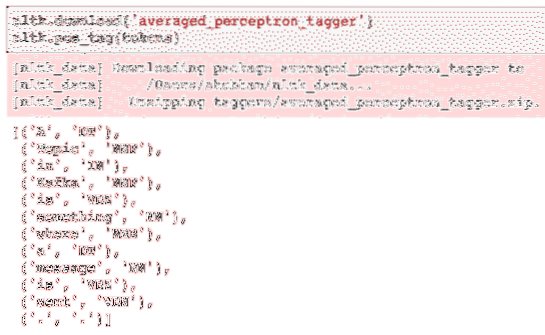
Nå som vi endelig har identifisert de merkede ordene, er dette datasettet som vi kan utføre sentimentanalyse for å identifisere følelsene bak en setning.
Konklusjon
I denne leksjonen så vi på en utmerket naturlig språkpakke, NLTK som lar oss jobbe med ustrukturerte tekstdata for å identifisere eventuelle stoppord og utføre dypere analyser ved å utarbeide et skarpt datasett for tekstanalyse med biblioteker som sklearn.
Finn all kildekoden som brukes i denne leksjonen på Github. Del din tilbakemelding på leksjonen på Twitter med @sbmaggarwal og @LinuxHint.


