For å komme i gang, må du ha MySQL installert på systemet ditt med verktøyene: MySQL arbeidsbenk og kommandolinjeklientskall. Etter det bør du ha noen data eller verdier i databasetabellene som duplikater. La oss utforske dette med noen eksempler. Først og fremst åpner du kommandolinjeklientskallet fra oppgavelinjen på skrivebordet og skriver inn MySQL-passordet ditt etter spørsmål.

Vi har funnet forskjellige metoder for å finne duplisert i en tabell. Ta en titt på dem en etter en.
Søk i duplikater i en enkelt kolonne
Først må du vite om syntaksen til spørringen som brukes til å sjekke og telle duplikater for en enkelt kolonne.
>> VELG kol TELL (kol) FRA tabell GRUPP FOR kol HAVTELL (kol)> 1;Her er forklaringen på spørringen ovenfor:
- Kolonne: Navnet på kolonnen som skal kontrolleres.
- TELLE(): funksjonen som brukes til å telle mange dupliserte verdier.
- GRUPPE AV: klausulen som ble brukt til å gruppere alle rader i henhold til den aktuelle kolonnen.
Vi har opprettet en ny tabell kalt 'dyr' i MySQL-databasen 'data' med duplikatverdier. Den har seks kolonner med forskjellige verdier i, f.eks.g., id, navn, art, kjønn, alder og pris som gir informasjon om forskjellige kjæledyr. Når du ringer til denne tabellen ved hjelp av SELECT-spørringen, får vi utdataene nedenfor på vårt MySQL-kommandolinjeklientskall.
>> VELG * FRA data.dyr;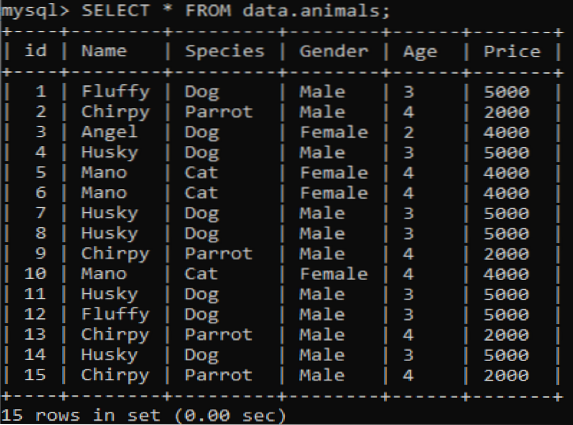
Nå vil vi prøve å finne de overflødige og gjentatte verdiene fra tabellen ovenfor ved å bruke COUNT og GROUP BY-setningen i SELECT-spørringen. Dette spørsmålet teller navnene på kjæledyr som ligger mindre enn 3 ganger i tabellen. Etter det vil det vise disse navnene som nedenfor.
>> VELG Navn TELL (navn) FRA data.dyr GRUPPER PÅ Navn HAR TELL (navn) < 3;
Ved å bruke den samme spørringen for å få forskjellige resultater mens du endrer COUNT-nummeret for navn på kjæledyr som vist nedenfor.
>> VELG Navn TELL (navn) FRA data.dyr GRUPPER PÅ Navn HAR TELL (navn)> 3;
For å få resultater for totalt 3 dupliserte verdier for navn på kjæledyr som vist nedenfor.
>> VELG Navn ANTALL (navn) FRA data.dyr GRUPPER PÅ Navn HAR TELL (navn) = 3;
Søk i duplikater i flere kolonner
Syntaksen til spørringen for å sjekke eller telle duplikater for flere kolonner er som følger:
>> VELG col1, COUNT (col1), col2, COUNT (col2) FRA tabell GROUP GROUP etter col1, col2 HAR COUNT (col1)> 1 AND COUNT (col2)> 1;Her er forklaringen på spørringen ovenfor:
- col1, col2: navnet på kolonnene som skal kontrolleres.
- TELLE(): funksjonen som brukes til å telle flere dupliserte verdier.
- GRUPPE AV: klausulen som ble brukt til å gruppere alle rader i henhold til den spesifikke kolonnen.
Vi har brukt den samme tabellen kalt "dyr" som har dupliserte verdier. Vi fikk utdataene nedenfor mens vi brukte spørringen ovenfor for å sjekke duplikatverdiene i flere kolonner. Vi har sjekket og telt duplikatverdiene for kolonnene Kjønn og pris mens de er gruppert etter kolonnen Pris. Det viser kjønnsdyrene og prisene som ligger i tabellen som duplikater, ikke mer enn 5.
>> VELG Kjønn, TELL (kjønn), Pris, TELL (Pris) FRA data.dyr GRUPPER PÅ PRIS HAR ANTALL (Pris) < 5 AND COUNT(Gender) < 5;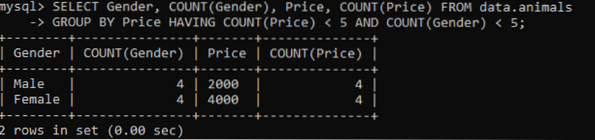
Søk etter duplikater i enkeltbord ved hjelp av INNER JOIN
Her er den grunnleggende syntaksen for å finne duplikater i en enkelt tabell:
>> VELG col1, col2, tabell.kol FRA tabell INNRE JOIN (VELG kol. FRA tabell GRUPPE PÅ kol HAVTELL (kol1)> 1) temp PÅ tabell.kol = temp.kol;Her er fortellingen om overhead-spørringen:
- Kol: navnet på kolonnen som skal kontrolleres og velges for duplikater.
- Temp: nøkkelord for å bruke indre sammenføyning i en kolonne.
- Bord: navnet på tabellen som skal kontrolleres.
Vi har en ny tabell, 'order2' med dupliserte verdier i kolonnen OrderNo som vist nedenfor.
>> VELG * FRA data.ordre2;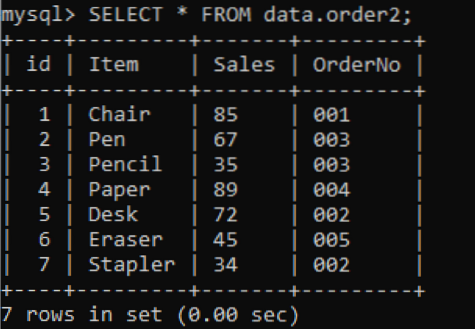
Vi velger tre kolonner: Vare, Salg, Bestillingsnummer som skal vises i utdataene. Mens kolonnen OrderNo brukes til å sjekke duplikater. Den indre sammenføyningen vil velge verdiene eller radene som har verdiene til Elementer mer enn en i en tabell. Etter gjennomføring vil vi få resultatene nedenfor.
>> VELG vare, salg, ordre2.OrderNo FROM data.order2 INNER JOIN (VELG OrderNr FRA data.ordre2 GRUPPE PÅ OrdreNO HAR TELL (vare)> 1) temp PÅ ordre2.Bestillingsnr = temp.Best.nr;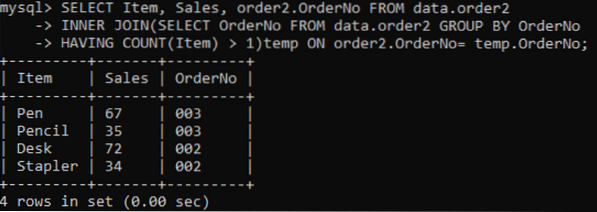
Søk i duplikater i flere tabeller ved hjelp av INNER JOIN
Her er den forenklede syntaksen for å finne duplikater i flere tabeller:
>> VELG kol. FRA tabell1 INNER JOIN tabell2 PÅ tabell1.kol = tabell2.kol;Her er beskrivelsen av overhead-spørringen:
- kol: navnet på kolonnene som skal kontrolleres og velges.
- INNRE MEDLEM: funksjonen som ble brukt til å bli med i to tabeller.
- PÅ: brukes til å slå sammen to tabeller i henhold til de angitte kolonnene.
Vi har to tabeller, 'order1' og 'order2', i databasen vår med kolonnen 'OrderNo' i begge som vist nedenfor.
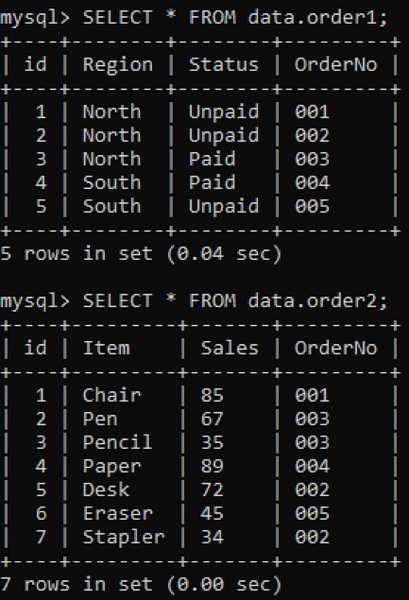
Vi bruker INNER-koblingen til å kombinere duplikatene av to tabeller i henhold til en spesifisert kolonne. INNER JOIN-leddet vil få alle dataene fra begge tabellene ved å bli med dem, og ON-leddet vil forholde seg til samme kolonner fra begge tabellene, e.g., Best.nr.
>> VELG * FRA data.order1 INNER JOIN data.ordre2 PÅ ordre1.OrderNo = order2.Best.nr;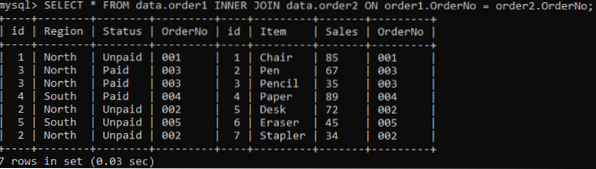
For å få bestemte kolonner i en utgang, prøv kommandoen nedenfor:
>> VELG Region, status, vare, salg fra data.order1 INNER JOIN data.ordre2 PÅ ordre1.OrderNo = order2.Best.nr;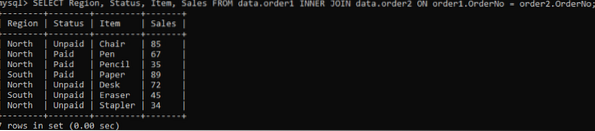
Konklusjon
Vi kunne nå søke etter flere kopier i en eller flere tabeller med MySQL-informasjon og gjenkjenne funksjonen GROUP BY, COUNT og INNER JOIN. Forsikre deg om at du har bygget tabellene riktig, og at de riktige kolonnene er valgt.


