Opplæring i nettskraping har blitt dekket tidligere, derfor dekker denne opplæringen bare aspektet ved å få tilgang til nettsteder ved å logge på med kode i stedet for å gjøre det manuelt ved å bruke nettleseren.
For å forstå denne veiledningen og være i stand til å skrive skript for innlogging på nettsteder, trenger du litt forståelse av HTML. Kanskje ikke nok til å bygge fantastiske nettsteder, men nok til å forstå strukturen til en grunnleggende webside.
Installasjon
Dette vil bli gjort med Requests og BeautifulSoup Python-biblioteker. I tillegg til disse Python-bibliotekene, vil du trenge en god nettleser som Google Chrome eller Mozilla Firefox, da de ville være viktige for innledende analyse før du skriver kode.
Forespørslene og BeautifulSoup-bibliotekene kan installeres med pip-kommandoen fra terminalen som vist nedenfor:
pip install forespørslerpip installer BeautifulSoup4
For å bekrefte suksessen med installasjonen, aktiver Pythons interaktive skall som gjøres ved å skrive python inn i terminalen.
Importer deretter begge bibliotekene:
importforespørslerfra bs4 import BeautifulSoup
Importen er vellykket hvis det ikke er noen feil.
Prosessen
Å logge inn på et nettsted med skript krever kunnskap om HTML og en ide om hvordan nettet fungerer. La oss kort se på hvordan nettet fungerer.
Nettsteder er laget av to hoveddeler, klientsiden og serversiden. Klientsiden er den delen av et nettsted som brukeren kommuniserer med, mens server-siden er den delen av nettstedet der forretningslogikk og andre serveroperasjoner som tilgang til databasen utføres.
Når du prøver å åpne et nettsted via koblingen, ber du serveren om å hente HTML-filene og andre statiske filer som CSS og JavaScript. Denne forespørselen er kjent som GET-forespørselen. Men når du fyller ut et skjema, laster opp en mediefil eller et dokument, oppretter et innlegg og klikker la oss si en innleveringsknapp, sender du informasjon til serversiden. Denne forespørselen er kjent som POST-forespørselen.
Å forstå disse to begrepene vil være viktig når du skriver manus.
Inspisere nettstedet
For å øve på konseptene i denne artikkelen bruker vi nettstedet Quotes To Scrape.
Innlogging på nettsteder krever informasjon som brukernavn og passord.
Men siden dette nettstedet bare brukes som et bevis på konseptet, går alt. Derfor bruker vi admin som brukernavn og 12345 som passord.
For det første er det viktig å se på sidekilden, da dette vil gi en oversikt over strukturen til websiden. Dette kan gjøres ved å høyreklikke på websiden og klikke på "Vis sidekilde". Deretter inspiserer du påloggingsskjemaet. Du gjør dette ved å høyreklikke på en av påloggingsboksene og klikke inspisér element. På inspeksjonselementet, bør du se inngang tagger og deretter en forelder skjema tag et sted over det. Dette viser at innlogginger i utgangspunktet er former POSTredigeres til serversiden av nettstedet.
Legg merke til Navn attributtet til inngangskodene for brukernavnet og passordboksene, ville de være nødvendige når du skriver koden. For dette nettstedet, Navn attributt for brukernavnet og passordet er brukernavn og passord henholdsvis.
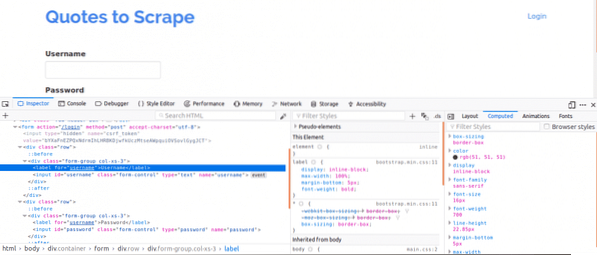
Deretter må vi vite om det er andre parametere som vil være viktige for pålogging. La oss raskt forklare dette. For å øke sikkerheten til nettsteder, genereres tokens vanligvis for å forhindre Cross Site Forgery-angrep.
Derfor, hvis disse tokens ikke blir lagt til POST-forespørselen, vil innloggingen mislykkes. Så hvordan vet vi om slike parametere?
Vi må bruke fanen Nettverk. For å få denne fanen på Google Chrome eller Mozilla Firefox, åpner du utviklerverktøyene og klikker på kategorien Nettverk.
Når du er i nettverksfanen, kan du prøve å oppdatere den gjeldende siden, og du vil merke at forespørsler kommer inn. Du bør prøve å passe på når du sender inn POST-forespørsler når vi prøver å logge inn.
Her er hva vi ville gjort videre mens vi hadde fanen Nettverk åpen. Legg inn påloggingsdetaljene og prøv å logge inn. Den første forespørselen du ser, bør være POST-forespørselen.
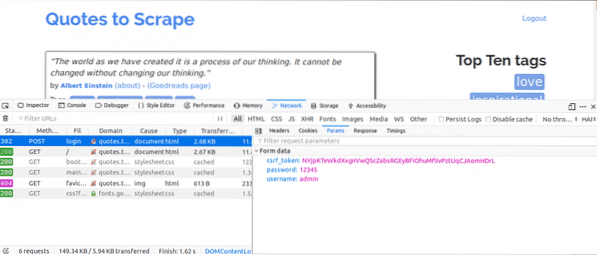
Klikk på POST-forespørselen og se skjemaparametrene. Du vil merke at nettstedet har en csrf_token parameter med en verdi. Denne verdien er en dynamisk verdi, derfor må vi fange slike verdier ved hjelp av FÅ forespørsel først før du bruker POST be om.
For andre nettsteder du jobber med, ser du sannsynligvis ikke csrf_token men det kan være andre tokens som genereres dynamisk. Over tid vil du bli bedre til å kjenne parametrene som virkelig betyr noe for å gjøre et påloggingsforsøk.
Koden
For det første må vi bruke Forespørsler og BeautifulSoup for å få tilgang til sideinnholdet på påloggingssiden.
fra forespørsel om importøktfra bs4 importerer BeautifulSoup som bs
med økt () som s:
nettsted = s.get ("http: // sitater.å skrape.com / login ")
skriv ut (nettsted.innhold)
Dette vil skrive ut innholdet på innloggingssiden før vi logger inn, og hvis du søker etter "Login" nøkkelordet. Nøkkelordet finnes i sideinnholdet som viser at vi ennå ikke skal logge inn.
Deretter ville vi søke etter csrf_token nøkkelord som ble funnet som en av parameterne når du brukte nettverksfanen tidligere. Hvis nøkkelordet viser et treff med en inngang merket, så kan verdien hentes ut hver gang du kjører skriptet ved hjelp av BeautifulSoup.
fra forespørsel om importøktfra bs4 importerer BeautifulSoup som bs
med økt () som s:
nettsted = s.get ("http: // sitater.å skrape.com / login ")
bs_content = bs (nettsted.innhold, "html.parser ")
token = bs_innhold.finn ("input", "name": "csrf_token") ["verdi"]
login_data = "brukernavn": "admin", "passord": "12345", "csrf_token": token
s.post ("http: // sitater.å skrape.com / login ", login_data)
home_page = s.get ("http: // sitater.å skrape.com ")
skriv ut (startside.innhold)
Dette vil skrive ut innholdet på siden etter innlogging, og hvis du søker etter søkeordet "Logout". Nøkkelordet ble funnet i sideinnholdet som viser at vi klarte å logge inn.
La oss ta en titt på hver kodelinje.
fra forespørsel om importøktfra bs4 importerer BeautifulSoup som bs
Kodelinjene ovenfor brukes til å importere øktobjektet fra forespørselsbiblioteket og BeautifulSoup-objektet fra bs4-biblioteket ved hjelp av et alias av bs.
med økt () som s:Forespørselsøkten brukes når du har tenkt å beholde konteksten til en forespørsel, slik at informasjonskapslene og all informasjon fra forespørselsøkten kan lagres.
bs_content = bs (nettsted.innhold, "html.parser ")token = bs_innhold.finn ("input", "name": "csrf_token") ["verdi"]
Denne koden bruker BeautifulSoup-biblioteket slik at csrf_token kan hentes fra nettsiden og deretter tilordnes tokenvariabelen. Du kan lære om å trekke ut data fra noder ved hjelp av BeautifulSoup.
login_data = "brukernavn": "admin", "passord": "12345", "csrf_token": tokens.post ("http: // sitater.å skrape.com / login ", login_data)
Koden her oppretter en ordliste over parametrene som skal brukes til pålogging. Nøklene til ordbøkene er Navn attributtene til inngangskodene og verdiene er verdi attributtene til inngangskodene.
De post metoden brukes til å sende en postforespørsel med parametrene og logge oss på.
home_page = s.get ("http: // sitater.å skrape.com ")skriv ut (startside.innhold)
Etter pålogging trekker disse kodelinjene ut ganske enkelt ut informasjonen fra siden for å vise at påloggingen var vellykket.
Konklusjon
Prosessen med å logge på nettsteder ved hjelp av Python er ganske enkel, men installasjonen av nettsteder er ikke den samme, derfor vil noen nettsteder være vanskeligere å logge på enn andre. Det er mer som kan gjøres for å overvinne hvilke påloggingsutfordringer du har.
Det viktigste i alt dette er kunnskapen om HTML, forespørsler, BeautifulSoup og muligheten til å forstå informasjonen du har fått fra nettverket-fanen i nettleserens utviklerverktøy.


