Dette er en oppfølgingsartikkel til den forrige. Vi vil dekke hvordan du kan avgrense spørringen, formulere mer komplekse søkekriterier med forskjellige parametere, og forstå Apache Solr-spørringssidens forskjellige nettformer. Vi vil også diskutere hvordan du kan behandle søkeresultatet etter forskjellige utdataformater som XML, CSV og JSON.
Spørring om Apache Solr
Apache Solr er designet som en webapplikasjon og -tjeneste som kjører i bakgrunnen. Resultatet er at ethvert klientprogram kan kommunisere med Solr ved å sende spørsmål til det (fokuset i denne artikkelen), manipulere dokumentkjernen ved å legge til, oppdatere og slette indekserte data og optimalisere kjernedata. Det er to alternativer - via dashbord / webgrensesnitt eller ved å bruke en API ved å sende en tilsvarende forespørsel.
Det er vanlig å bruke første alternativet for testformål og ikke for vanlig tilgang. Figuren nedenfor viser dashbordet fra Apache Solr Administration User Interface med de forskjellige spørreskjemaene i nettleseren Firefox.
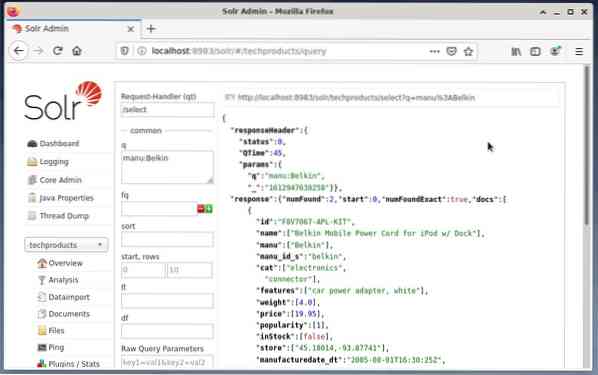
Velg først menyoppføringen "Spørring" fra menyen under kjernevalgfeltet. Deretter vil dashbordet vise flere inntastingsfelt som følger:
- Forespørselsbehandler (qt):
Definer hva slags forespørsel du vil sende til Solr. Du kan velge mellom standardforespørselsbehandlerne "/ select" (spørringsindekserte data), "/ update" (oppdater indekserte data) og "/ delete" (fjern de angitte indekserte dataene), eller en selvdefinert. - Spørringshendelse (q):
Definer hvilke feltnavn og verdier som skal velges. - Filtrer spørringer (fq):
Begrens supersettet av dokumenter som kan returneres uten å påvirke dokumentpoengene. - Sortering (sortering):
Definer sorteringsrekkefølgen for søkeresultatene til enten stigende eller synkende - Utgangsvindu (start og rader):
Begrens utgangen til de angitte elementene - Feltliste (fl):
Begrenser informasjonen som er inkludert i et spørresvar, til en spesifisert feltliste. - Utdataformat (wt):
Definer ønsket format. Standardverdien er JSON.
Ved å klikke på Utfør spørring-knappen kjøres ønsket forespørsel. For praktiske eksempler, se nedenfor.
Som den andre alternativet, du kan sende en forespørsel ved hjelp av et API. Dette er en HTTP-forespørsel som kan sendes til Apache Solr av alle applikasjoner. Solr behandler forespørselen og returnerer et svar. Et spesielt tilfelle av dette er å koble til Apache Solr via Java API. Dette er outsourcet til et eget prosjekt kalt SolrJ [7] - et Java API uten å kreve en HTTP-forbindelse.
Spørringssyntaks
Søkesyntaks blir best beskrevet i [3] og [5]. De forskjellige parameternavnene samsvarer direkte med navnene på inntastingsfeltene i skjemaene som er forklart ovenfor. Tabellen nedenfor viser dem, pluss praktiske eksempler.
Query Parameters Index
| Parameter | Beskrivelse | Eksempel |
|---|---|---|
| q | Hovedspareparameteren til Apache Solr - feltnavn og verdier. Deres likhetspoeng dokumenterer til vilkårene i denne parameteren. | Id: 5 biler: * adilla * *: X5 |
| fq | Begrens resultatsettet til supersettdokumentene som samsvarer med filteret, for eksempel definert via funksjonsområde spørringsparser | modell id, modell |
| start | Forskyvninger for sideresultater (begynn). Standardverdien for denne parameteren er 0. | 5 |
| rader | Forskyvninger for sideresultater (slutt). Verdien til denne parameteren er 10 som standard | 15 |
| sortere | Den spesifiserer listen over felt atskilt med komma, basert på hvilke søkeresultatene skal sorteres | modell asc |
| fl | Den spesifiserer listen over feltene som skal returneres for alle dokumentene i resultatsettet | modell id, modell |
| wt | Denne parameteren representerer typen responsforfatter vi ønsket å se resultatet. Verdien av dette er JSON som standard. | json xml |
Søk gjøres via HTTP GET-forespørsel med spørringsstrengen i q-parameteren. Eksemplene nedenfor vil avklare hvordan dette fungerer. I bruk er krøll for å sende spørringen til Solr som er installert lokalt.
- Hent alle datasettene fra kjernevognens krøll http: // localhost: 8983 / solr / cars / query?q = *: *
- Hent alle datasettene fra kjernebilene som har en id på 5 curl http: // localhost: 8983 / solr / cars / query?q = id: 5
- Hent feltmodellen fra alle datasettene til kjernebilene
Alternativ 1 (med rømt og): krølle http: // localhost: 8983 / solr / biler / spørring?q = id: * \ & fl = modellAlternativ 2 (spørsmål i enkle kryss):
curl 'http: // localhost: 8983 / solr / cars / query?q = id: * & fl = modell ' - Hent alle datasettene til kjernebilene sortert etter pris i synkende rekkefølge, og skriv kun ut feltene fabrikat, modell og pris (versjon i enkelt kryss): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
sorter = prisbeskrivelse
fl = merke, modell, pris ' - Hent de fem første datasettene til kjernebilene sortert etter pris i synkende rekkefølge, og skriv ut bare feltene fabrikat, modell og pris (versjon i enkle kryss): curl http: // localhost: 8983 / solr / cars / query - d '
q = *: * &
rader = 5 &
sorter = prisbeskrivelse &
fl = merke, modell, pris ' - Hent de fem første datasettene til kjernebilene sortert etter pris i synkende rekkefølge, og skriv ut feltene fabrikat, modell og pris pluss dens relevanspoeng, bare (versjon i enkelt kryss): krøll http: // localhost: 8983 / solr / biler / spørring -d '
q = *: * &
rader = 5 &
sorter = prisbeskrivelse
fl = merke, modell, pris, poengsum ' - Returner alle lagrede felt samt relevanspoeng: curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
fl = *, score '
Videre kan du definere din egen forespørselsbehandler for å sende de valgfrie forespørselsparametrene til spørringsparseren for å kontrollere hvilken informasjon som returneres.
Spørringsparsere
Apache Solr bruker en såkalt spørringsparser - en komponent som oversetter søkestrengen din til spesifikke instruksjoner for søkemotoren. En spørringsparser står mellom deg og dokumentet du leter etter.
Solr kommer med en rekke parsertyper som varierer i måten et innsendt spørsmål håndteres på. Standard Query Parser fungerer bra for strukturerte spørsmål, men er mindre tolerant for syntaksfeil. Samtidig er både DisMax og Extended DisMax Query Parser optimalisert for naturlige språklignende spørsmål. De er designet for å behandle enkle setninger som er skrevet inn av brukerne, og for å søke etter individuelle begreper på tvers av flere felt ved hjelp av annen vekting.
Videre tilbyr Solr også såkalte Function Queries som gjør det mulig å kombinere en funksjon med et spørsmål for å generere en spesifikk relevanspoeng. Disse parserne er kalt Function Query Parser og Function Range Query Parser. Eksemplet nedenfor viser sistnevnte for å velge alle datasettene for “bmw” (lagret i datafeltet fabrikat) med modellene fra 318 til 323:
curl http: // localhost: 8983 / solr / cars / query -d 'q = merke: bmw &
fq = modell: [318 TIL 323] '
Etterbehandling av resultater
Å sende spørsmål til Apache Solr er en del, men etterbehandling av søkeresultatet fra den andre. Først kan du velge mellom forskjellige responsformater - fra JSON til XML, CSV og et forenklet Ruby-format. Bare spesifiser den tilsvarende wt-parameteren i et spørsmål. Kodeeksemplet nedenfor viser dette for å hente datasettet i CSV-format for alle elementene ved hjelp av krøll med rømt &:
curl http: // localhost: 8983 / solr / cars / query?q = id: 5 \ & wt = csvUtgangen er en komma-skilt liste som følger:

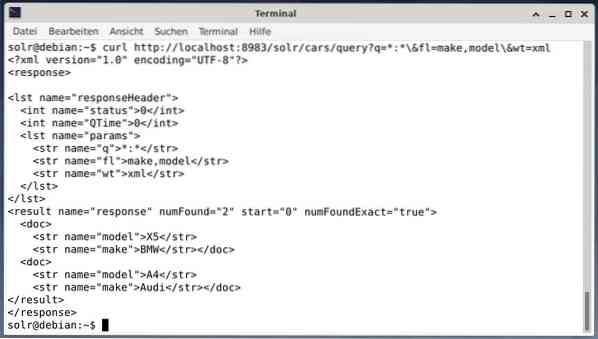
For å motta resultatet som XML-data, men bare de to utgangsfeltene lage og modell, kjør følgende spørring:
krølle http: // localhost: 8983 / solr / biler / spørring?q = *: * \ & fl = merke, modell \ & wt = xmlUtgangen er annerledes og inneholder både responsoverskriften og den faktiske responsen:
Wget skriver bare ut mottatte data på stdout. Dette lar deg etterbehandle svaret ved hjelp av standard kommandolinjeverktøy. For å liste noen få inneholder dette jq [9] for JSON, xsltproc, xidel, xmlstarlet [10] for XML samt csvkit [11] for CSV-format.
Konklusjon
Denne artikkelen viser forskjellige måter å sende spørsmål til Apache Solr og forklarer hvordan du behandler søkeresultatet. I neste del vil du lære hvordan du bruker Apache Solr til å søke i PostgreSQL, et relasjonelt databasestyringssystem.
Om forfatterne
Jacqui Kabeta er miljøverner, ivrig forsker, trener og mentor. I flere afrikanske land har hun jobbet i IT-bransjen og NGO-miljøer.
Frank Hofmann er IT-utvikler, trener og forfatter og foretrekker å jobbe fra Berlin, Genève og Cape Town. Medforfatter av Debian Package Management Book tilgjengelig fra dpmb.org
Lenker og referanser
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann og Jacqui Kabeta: Introduksjon til Apache Solr. Del 1, http: // linuxhint.com
- [3] Yonik Seelay: Solr Query Syntax, http: // yonik.com / solr / spørringssyntaks /
- [4] Yonik Seelay: Solr Tutorial, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: Querying Data, Tutorialspoint, https: // www.tutorialspoint.no / apache_solr / apache_solr_querying_data.htm
- [6] Lucene, https: // lucene.apache.org /
- [7] SolrJ, https: // lucene.apache.org / solr / guide / 8_8 / using-solrj.html
- [8] krøll, https: // krøll.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.sourceforge.nett/
- [11] csvkit, https: // csvkit.readthedocs.io / no / siste /


