Apache Spark er et dataanalyseverktøy som kan brukes til å behandle data fra HDFS, S3 eller andre datakilder i minnet. I dette innlegget installerer vi Apache Spark på en Ubuntu 17.10 maskin.
Ubuntu-versjon
For denne guiden vil vi bruke Ubuntu versjon 17.10 (GNU / Linux 4.1. 3.0-38-generisk x86_64).
Apache Spark er en del av Hadoop-økosystemet for Big Data. Prøv å installere Apache Hadoop og lag et prøveprogram med det.
Oppdaterer eksisterende pakker
For å starte installasjonen for Spark, er det nødvendig at vi oppdaterer maskinen vår med de nyeste tilgjengelige programvarepakkene. Vi kan gjøre dette med:
sudo apt-get update && sudo apt-get -y dist-upgradeEttersom Spark er basert på Java, må vi installere det på maskinen vår. Vi kan bruke hvilken som helst Java-versjon over Java 6. Her skal vi bruke Java 8:
sudo apt-get -y install openjdk-8-jdk-headlessLaste ned Spark-filer
Alle nødvendige pakker finnes nå på maskinen vår. Vi er klare til å laste ned de nødvendige Spark TAR-filene slik at vi kan begynne å konfigurere dem og kjøre et eksempelprogram med Spark også.
I denne guiden skal vi installere Gnist v2.3.0 tilgjengelig her:
Gnist nedlastingsside
Last ned de tilsvarende filene med denne kommandoen:
wget http: // www-us.apache.org / dist / gnist / gnist-2.3.0 / gnist-2.3.0-bin-hadoop2.7.tgzAvhengig av nettverkshastigheten kan dette ta opptil noen minutter siden filen er stor:
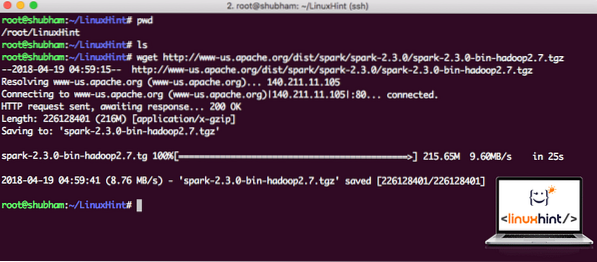
Laster ned Apache Spark
Nå som vi har lastet ned TAR-filen, kan vi trekke ut den i den nåværende katalogen:
tjære xvzf gnist-2.3.0-bin-hadoop2.7.tgzDette vil ta noen sekunder å fullføre på grunn av arkivens store filstørrelse:
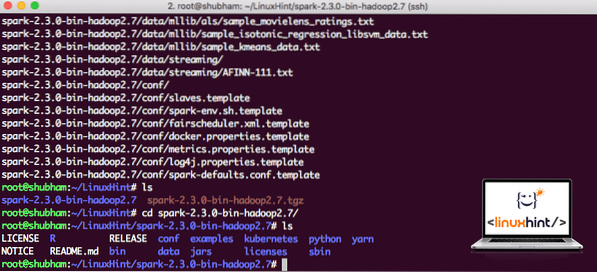
Ikke arkiverte filer i Spark
Når det gjelder oppgradering av Apache Spark i fremtiden, kan det skape problemer på grunn av baneoppdateringer. Disse problemene kan unngås ved å opprette en softlink til Spark. Kjør denne kommandoen for å lage en softlink:
ln -s gnist-2.3.0-bin-hadoop2.7 gnistLegger til gnist til bane
For å utføre Spark-skript, legger vi det til banen nå. For å gjøre dette, åpne bashrc-filen:
vi ~ /.bashrcLegg til disse linjene på slutten av .bashrc-fil slik at banen kan inneholde den eksekverbare filbanen Spark:
SPARK_HOME = / LinuxHint / gnisteksporter PATH = $ SPARK_HOME / bin: $ PATH
Nå ser filen ut som:
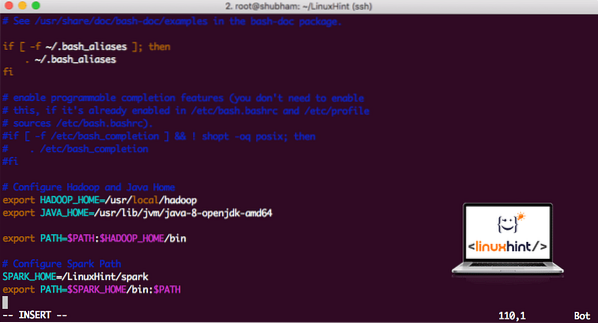
Legger til gnist til PATH
For å aktivere disse endringene, kjør følgende kommando for bashrc-fil:
kilde ~ /.bashrcLanserer Spark Shell
Nå når vi er rett utenfor gnistkatalogen, kjører du følgende kommando for å åpne apark shell:
./ gnist / søppel / gnistskallVi vil se at Spark shell er åpen nå:
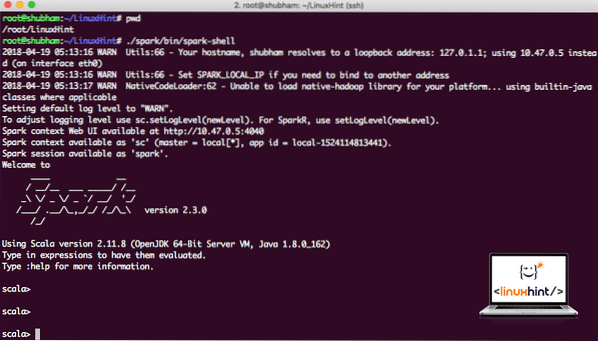
Lanserer gnistskall
Vi kan se i konsollen at Spark også har åpnet en nettkonsoll på port 404. La oss besøke det:
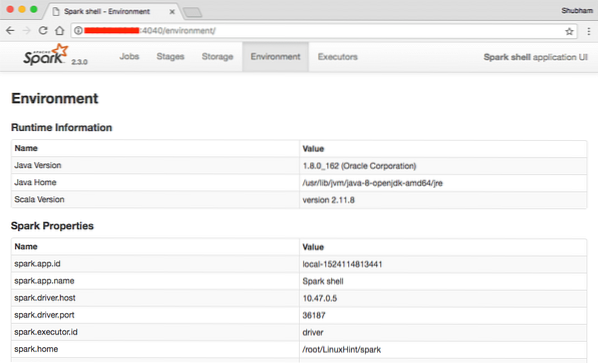
Apache Spark Web Console
Selv om vi skal operere på selve konsollen, er nettmiljø et viktig sted å se på når du utfører tunge gnistjobber slik at du vet hva som skjer i hver gnistjobb du utfører.
Sjekk Spark shell-versjonen med en enkel kommando:
sc.versjonVi får tilbake noe sånt som:
res0: Streng = 2.3.0Lage en prøve Gnistapplikasjon med Scala
Nå skal vi lage et eksempel på en Word Counter-applikasjon med Apache Spark. For å gjøre dette, last først en tekstfil i Spark Context på Spark shell:
scala> var Data = sc.textFile ("/ root / LinuxHint / spark / README.md ")Data: org.apache.gnist.rdd.RDD [String] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] ved textFile kl: 24
scala>
Nå må teksten i filen deles inn i tokens som Spark kan administrere:
scala> var tokens = Data.flatMap (s => s.split (""))tokens: org.apache.gnist.rdd.RDD [String] = MapPartitionsRDD [2] på flatMap kl: 25
scala>
Initialiser nå tellingen for hvert ord til 1:
scala> var tokens_1 = tokens.kart (s => (s, 1))tokens_1: org.apache.gnist.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] på kart ved: 25
scala>
Til slutt beregner du hyppigheten til hvert ord i filen:
var sum_each = tokens_1.redusereByKey ((a, b) => a + b)På tide å se på utdataene for programmet. Samle tokens og deres respektive tellinger:
scala> sum_each.samle inn()res1: Array [(String, Int)] = Array ((pakke, 1), (For, 3), (Programmer, 1), (prosessering.,1), (Fordi, 1), (The, 1), (side] (http: // gnist.apache.org / dokumentasjon.html).,1), (klynge.,1), (its, 1), ([run, 1), (than, 1), (APIs, 1), (have, 1), (Try, 1), (computation, 1), (through, 1 ), (flere, 1), (Dette, 2), (graf, 1), (Hive, 2), (lagring, 1), (["Spesifisering, 1), (Til, 2), (" garn " , 1), (En gang, 1), (["Nyttig, 1), (foretrekker, 1), (SparkPi, 2), (motor, 1), (versjon, 1), (fil, 1), (dokumentasjon ,, 1), (bearbeiding ,, 1), (the, 24), (are, 1), (systems.,1), (params, 1), (not, 1), (different, 1), (refer, 2), (Interactive, 2), (R ,, 1), (gitt.,1), (if, 4), (build, 4), (when, 1), (be, 2), (Tests, 1), (Apache, 1), (thread, 1), (programs ,, 1 ), (inkludert, 4), (./ bin / run-example, 2), (Spark.,1), (pakke.,1), (1000).count (), 1), (Versions, 1), (HDFS, 1), (D…
scala>
Utmerket! Vi klarte å kjøre et enkelt Word Counter-eksempel ved å bruke Scala-programmeringsspråk med en tekstfil som allerede er tilstede i systemet.
Konklusjon
I denne leksjonen så vi på hvordan vi kan installere og begynne å bruke Apache Spark på Ubuntu 17.10 maskin og kjør en prøveapplikasjon på den også.
Les flere Ubuntu-baserte innlegg her.


