Apache Hadoop er en stor dataløsning for lagring og analyse av store datamengder. I denne artikkelen vil vi detaljere de komplekse installasjonstrinnene for Apache Hadoop for å komme i gang med det på Ubuntu så raskt som mulig. I dette innlegget installerer vi Apache Hadoop på en Ubuntu 17.10 maskin.
Ubuntu-versjon
For denne guiden vil vi bruke Ubuntu versjon 17.10 (GNU / Linux 4.1. 3.0-38-generisk x86_64).
Oppdaterer eksisterende pakker
For å starte installasjonen for Hadoop er det nødvendig at vi oppdaterer maskinen vår med de nyeste tilgjengelige programvarepakkene. Vi kan gjøre dette med:
sudo apt-get update && sudo apt-get -y dist-upgradeEttersom Hadoop er basert på Java, må vi installere det på maskinen vår. Vi kan bruke hvilken som helst Java-versjon over Java 6. Her skal vi bruke Java 8:
sudo apt-get -y install openjdk-8-jdk-headlessLaster ned Hadoop-filer
Alle nødvendige pakker finnes nå på maskinen vår. Vi er klare til å laste ned de nødvendige Hadoop TAR-filene slik at vi kan begynne å konfigurere dem og kjøre et eksempelprogram med Hadoop også.
I denne guiden skal vi installere Hadoop v3.0.1. Last ned de tilsvarende filene med denne kommandoen:
wget http: // speil.cc.columbia.edu / pub / programvare / apache / hadoop / common / hadoop-3.0.1 / hadoop-3.0.1.tjære.gzAvhengig av nettverkshastigheten kan dette ta opptil noen minutter siden filen er stor:
Laster ned Hadoop
Finn de siste Hadoop-binærfiler her. Nå som vi har lastet ned TAR-filen, kan vi trekke ut den i den nåværende katalogen:
tjære xvzf hadoop-3.0.1.tjære.gzDette vil ta noen sekunder å fullføre på grunn av arkivens store filstørrelse:
Hadoop ble ikke arkivert
Lagt til en ny Hadoop-brukergruppe
Ettersom Hadoop opererer over HDFS, kan et nytt filsystem også forstyrre vårt eget filsystem på Ubuntu-maskinen. For å unngå denne kollisjonen oppretter vi en helt egen brukergruppe og tilordner den til Hadoop slik at den inneholder sine egne tillatelser. Vi kan legge til en ny brukergruppe med denne kommandoen:
addgroup hadoopVi får se noe sånt som:
Legger til Hadoop brukergruppe
Vi er klare til å legge til en ny bruker i denne gruppen:
useradd -G hadoop hadoopuserVær oppmerksom på at alle kommandoene vi kjører er som selve rotbrukeren. Med aove-kommando klarte vi å legge til en ny bruker i gruppen vi opprettet.
For å tillate Hadoop-brukere å utføre operasjoner, må vi også gi den root-tilgang. Åpne / etc / sudoers fil med denne kommandoen:
sudo visudoFør vi legger til noe, vil filen se ut som:
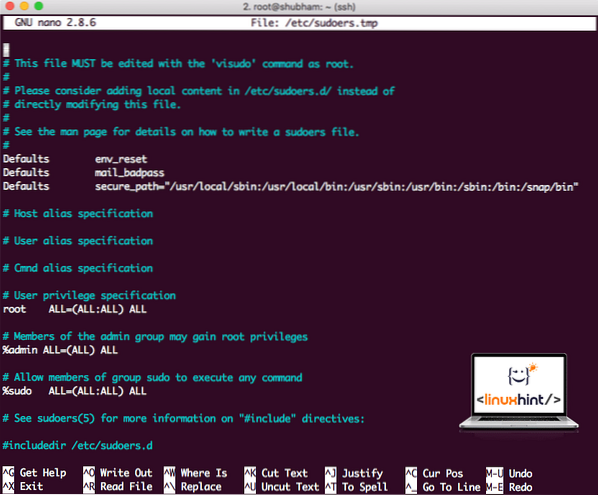
Sudoers arkivere før du legger til noe
Legg til følgende linje på slutten av filen:
hadoopuser ALL = (ALL) ALLNå vil filen se ut:
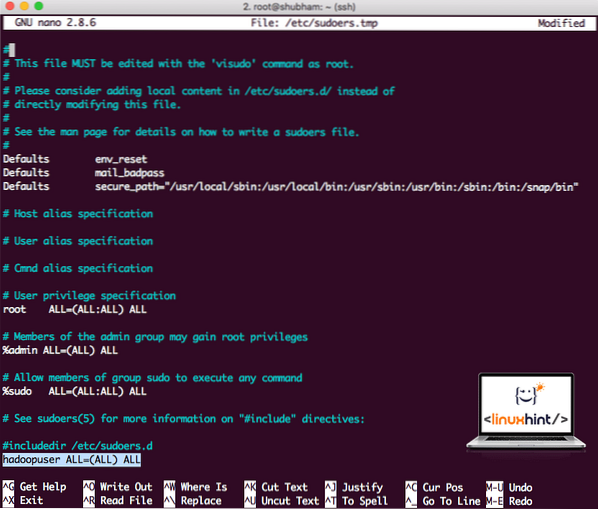
Sudoers-fil etter å ha lagt til Hadoop-bruker
Dette var hovedoppsettet for å gi Hadoop en plattform for å utføre handlinger. Vi er klare til å sette opp en enkelt node Hadoop-klynge nå.
Hadoop Single Node Setup: Frittstående modus
Når det kommer til den virkelige kraften til Hadoop, er den vanligvis satt opp på tvers av flere servere slik at den kan skaleres på toppen av en stor mengde datasett som er tilstede i Hadoop distribuert filsystem (HDFS). Dette er vanligvis bra med feilsøkingsmiljøer og brukes ikke til produksjonsbruk. For å holde prosessen enkel, vil vi forklare hvordan vi kan gjøre et enkelt nodeoppsett for Hadoop her.
Når vi er ferdig med å installere Hadoop, kjører vi også et eksempel på Hadoop. Per nå heter Hadoop-filen som hadoop-3.0.1. la oss gi den nytt navn til hadoop for enklere bruk:
mv hadoop-3.0.1 hadoopFilen ser nå ut som:
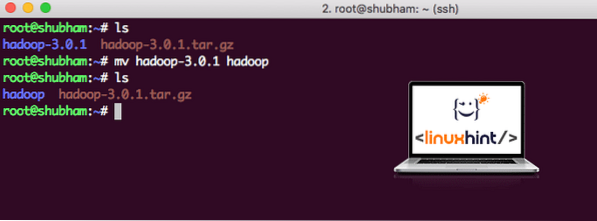
Flytter Hadoop
På tide å bruke hadoop-brukeren vi opprettet tidligere og tildele eierskapet til denne filen til den brukeren:
chown -R hadoopuser: hadoop / root / hadoopEt bedre sted for Hadoop vil være / usr / local / katalogen, så la oss flytte den dit:
mv hadoop / usr / lokal /cd / usr / lokal /
Legge til Hadoop til Path
For å utføre Hadoop-skript, legger vi det til banen nå. For å gjøre dette, åpne bashrc-filen:
vi ~ /.bashrcLegg til disse linjene på slutten av .bashrc-fil slik at banen kan inneholde Hadoop-kjørbare filsti:
# Konfigurer Hadoop og Java Homeeksporter HADOOP_HOME = / usr / local / hadoop
eksporter JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64
eksporter PATH = $ PATH: $ HADOOP_HOME / bin
Filen ser ut som:
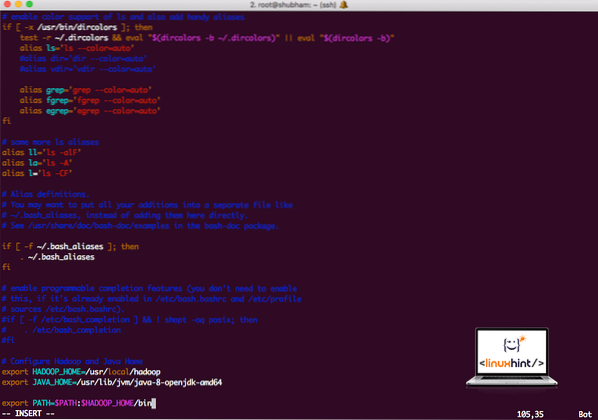
Legge til Hadoop til Path
Ettersom Hadoop bruker Java, må vi fortelle Hadoop-miljøfilen hadoop-env.sh der den ligger. Plasseringen av denne filen kan variere basert på Hadoop-versjoner. For å enkelt finne hvor denne filen ligger, kjør følgende kommando rett utenfor Hadoop-katalogen:
finn hadoop / -navn hadoop-env.shVi får utdataene for filplasseringen:
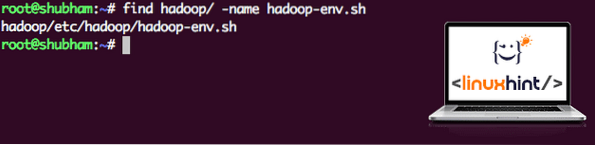
Plassering av miljøfil
La oss redigere denne filen for å informere Hadoop om Java JDK-plasseringen og sette inn denne på den siste linjen i filen og lagre den:
eksporter JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64Hadoop installasjon og oppsett er nå fullført. Vi er klare til å kjøre eksempelsøknaden vår nå. Men vent, vi har aldri laget en prøvesøknad!
Kjører prøveapplikasjon med Hadoop
Egentlig kommer Hadoop-installasjonen med et innebygd prøveprogram som er klart til å kjøres når vi er ferdige med å installere Hadoop. Høres bra ut, ikke sant?
Kjør følgende kommando for å kjøre JAR-eksemplet:
hadoop jar / root / hadoop / share / hadoop / mapreduce / hadoop-mapreduce-examples-3.0.1.jar wordcount / root / hadoop / README.txt / root / OutputHadoop vil vise hvor mye behandling det gjorde på noden:
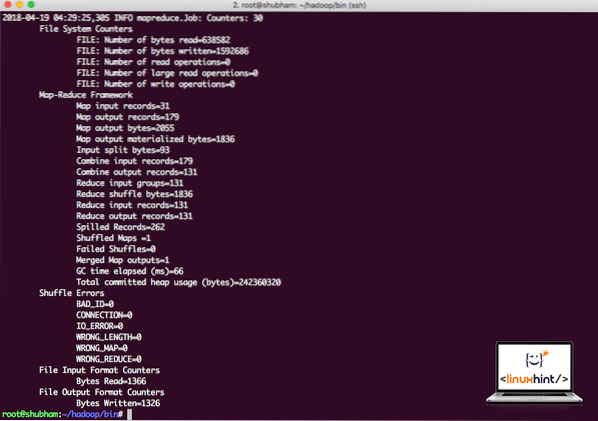
Hadoop-behandlingsstatistikk
Når du har utført følgende kommando, ser vi filen del-r-00000 som en utgang. Gå videre og se på innholdet i utdataene:
katt del-r-00000Du får noe sånt som:
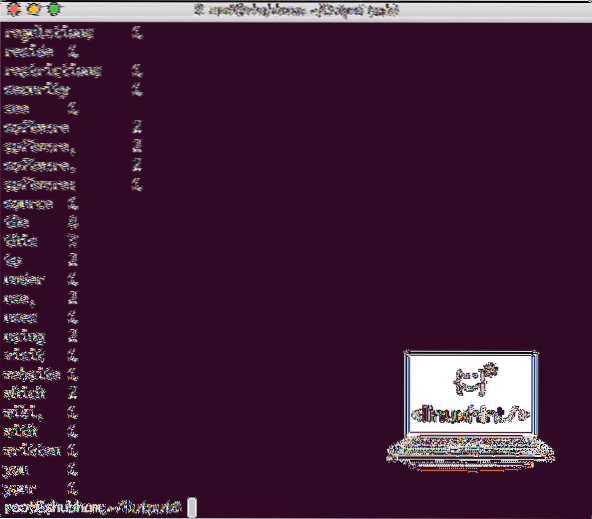
Word Count-utdata fra Hadoop
Konklusjon
I denne leksjonen så vi på hvordan vi kan installere og begynne å bruke Apache Hadoop på Ubuntu 17.10 maskin. Hadoop er flott for lagring og analyse av enorme mengder data, og jeg håper denne artikkelen vil hjelpe deg med å komme raskt i gang med å bruke den på Ubuntu.


