I denne artikkelen vil vi gå gjennom de grunnleggende bruken av en gruppe etter funksjon i pandas python. Alle kommandoer kjøres på Pycharm-redigereren.
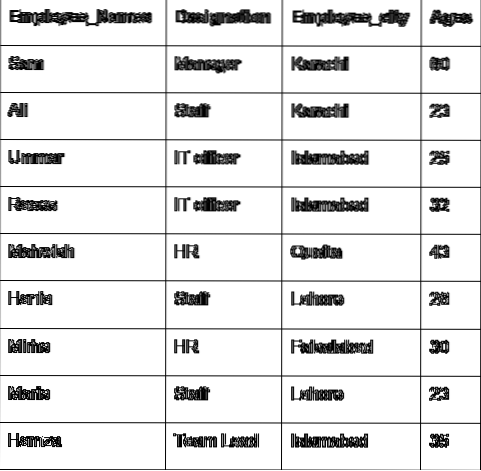
La oss diskutere hovedkonseptet til gruppen ved hjelp av de ansattes data. Vi har laget en dataramme med nyttige medarbeideropplysninger (ansatt_Navn, betegnelse, ansatt_stad, alder).
Strengsammenkobling ved hjelp av Gruppe etter funksjon
Ved hjelp av groupby-funksjonen kan du sammenkoble strenger. Samme poster kan slås sammen med ',' i en enkelt celle.
Eksempel
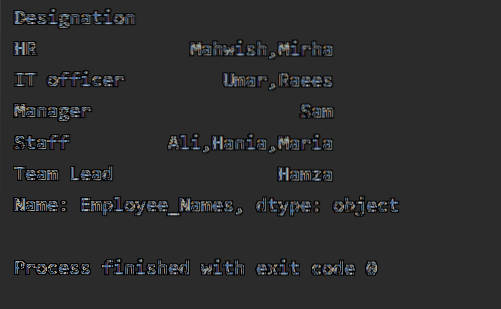
I det følgende eksemplet har vi sortert data basert på ansattes 'Betegnelse' -kolonne og sluttet seg til de ansatte som har samme betegnelse. Lambda-funksjonen brukes på 'Ansatte_navn'.
importer pandaer som pddf = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ("Betegnelse") ['Employee_Names'].gjelder (lambda Employee_Names: ','.bli med (Employee_Names))
skriv ut (df1)
Når koden ovenfor kjøres, vises følgende utgang:
Sortering av verdier i stigende rekkefølge
Bruk groupby-objektet til en vanlig dataramme ved å ringe '.to_frame () 'og bruk deretter reset_index () for reindeksering. Sorter kolonneverdier ved å ringe sort_values ().
Eksempel
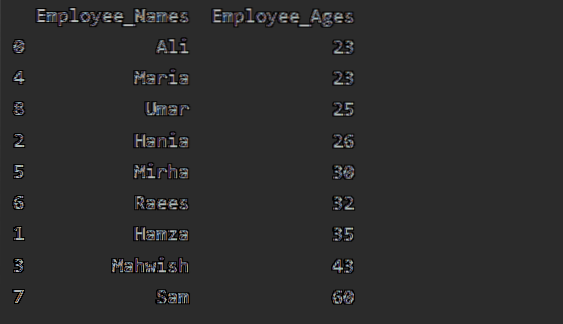
I dette eksemplet vil vi sortere ansattes alder i stigende rekkefølge. Ved å bruke følgende kode, har vi hentet 'Employee_Age' i stigende rekkefølge med 'Employee_Names'.
importer pandaer som pddf = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].sum().å ramme inn().reset_index ().sort_values (by = 'Employee_Age')
skriv ut (df1)
Bruk av aggregater med groupby
Det er en rekke funksjoner eller aggregeringer tilgjengelig som du kan bruke på datagrupper som count (), sum (), mean (), median (), mode (), std (), min (), max ().
Eksempel
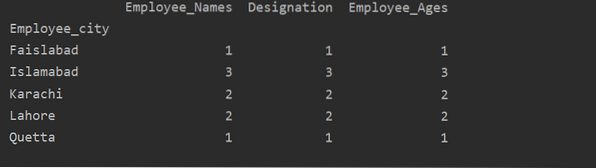
I dette eksemplet har vi brukt en 'count ()' - funksjon med groupby for å telle de ansatte som tilhører samme 'Employee_city'.
importer pandaer som pddf = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city').telle()
skriv ut (df1)
Som du kan se følgende utdata, teller tall som tilhører samme by under kolonnene Betegnelse, Ansatte_Navn og Ansatt_Age:
Visualiser data ved hjelp av groupby
Ved å bruke 'import matplotlib.pyplot ', kan du visualisere dataene dine i grafer.
Eksempel
Her visualiserer følgende eksempel 'Employee_Age' med 'Employee_Nmaes' fra den gitte DataFrame ved å bruke groupby-setningen.
importer pandaer som pdimporter matplotlib.pyplot som plt
dataframe = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
Dataramme.groupby ('Employee_Names').sum().tomt (kind = 'bar')
plt.vise fram()
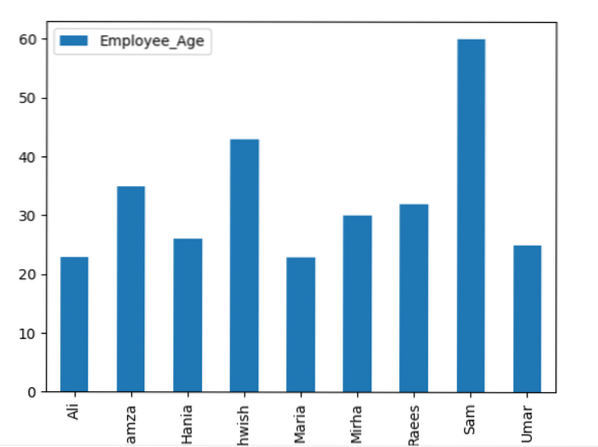
Eksempel
For å plotte den stablede grafen ved hjelp av groupby, snu 'stacked = true' og bruk følgende kode:
importer pandaer som pdimporter matplotlib.pyplot som plt
df = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby (['Employee_city', 'Employee_Names']).størrelse().unstack ().plot (kind = 'bar', stacked = True, fontsize = '6')
plt.vise fram()
I nedenstående graf er antallet ansatte stablet som tilhører samme by.
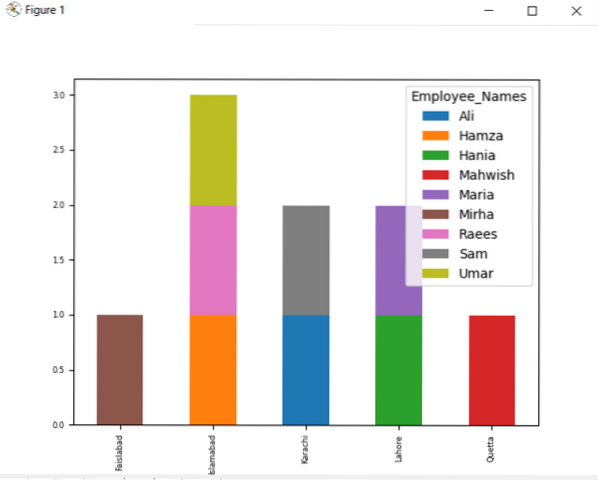
Endre kolonnenavn med gruppen etter
Du kan også endre det samlede kolonnenavnet med et nytt modifisert navn som følger:
importer pandaer som pdimporter matplotlib.pyplot som plt
df = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Betegnelse'].sum().reset_index (name = 'Employee_Designation')
skriv ut (df1)
I eksemplet ovenfor blir navnet 'Betegnelse' endret til 'Ansatt_Designasjon'.
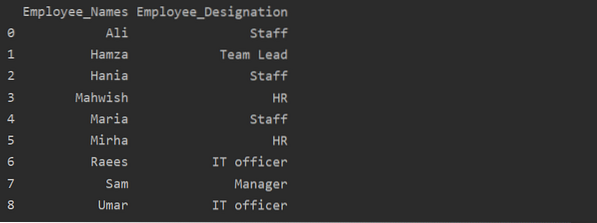
Hent gruppe etter nøkkel eller verdi
Ved å bruke groupby-setningen kan du hente lignende poster eller verdier fra datarammen.
Eksempel
I eksemplet nedenfor har vi gruppedata basert på 'Betegnelse'. Deretter hentes gruppen 'Staff' ved å bruke .getgroup ('Staff').
importer pandaer som pdimporter matplotlib.pyplot som plt
df = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
extract_value = df.groupby ('Betegnelse')
skriv ut (extract_value.get_group ('Staff'))
Følgende resultat vises i utgangsvinduet:

Legg til verdi i gruppelisten
Lignende data kan vises i form av en liste ved å bruke groupby-setningen. Først grupperer du dataene basert på en tilstand. Deretter, ved å bruke funksjonen, kan du enkelt sette denne gruppen i listene.
Eksempel
I dette eksemplet har vi satt inn lignende poster i gruppelisten. Alle ansatte er delt inn i gruppen basert på 'Employee_city', og ved å bruke 'Lambda' -funksjonen blir denne gruppen hentet i form av en liste.
importer pandaer som pddf = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].gjelder (lambda group_series: group_series.å liste opp()).reset_index ()
skriv ut (df1)
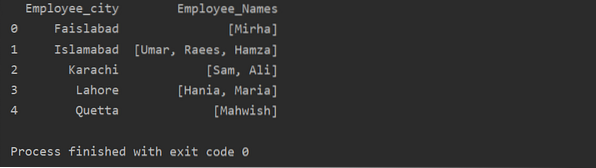
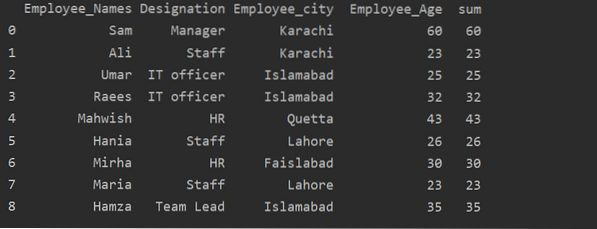
Bruk av Transform-funksjon med groupby
Ansatte er gruppert etter alder, disse verdiene er lagt sammen, og ved å bruke transformasjonsfunksjonen blir ny kolonne lagt til i tabellen:
importer pandaer som pddf = pd.Dataramme(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Betegnelse': ['Manager', 'Staff', 'IT officer', 'IT officer', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['sum'] = df.groupby (['Employee_Names']) ['Employee_Age'].transformere ('sum')
skrive ut (df)
Konklusjon
Vi har utforsket de forskjellige bruksområdene fra groupby-uttalelser i denne artikkelen. Vi har vist hvordan du kan dele dataene i grupper, og ved å bruke forskjellige aggregasjoner eller funksjoner, kan du enkelt hente disse gruppene.


