Vi vil utforske bruken av flettefunksjon, konkatfunksjon og forskjellige typer sammenføyningsoperasjoner i Pandas python i denne artikkelen. Alle eksempler blir utført gjennom pycharm-redigereren. La oss starte med detaljene!
Bruk av Flettefunksjon
Den grunnleggende ofte brukte syntaksen for merge () -funksjonen er gitt nedenfor:
pd.flette (df_obj1, df_obj2, how = 'indre', på = Ingen, left_on = Ingen, right_on = Ingen)La oss forklare detaljene i parametrene:
De to første df_obj1 og df_obj2 argumenter er navnene på DataFrame-objektene eller -tabellene.
“hvordan”-Parameter brukes til forskjellige typer sammenkoblingsoperasjoner som“ venstre, høyre, ytre og indre ”. Sammenslåingsfunksjonen bruker "indre" sammenkoblingsoperasjon som standard.
Argumentet "på" inneholder kolonnenavnet som tilknytningsoperasjonen utføres på. Denne kolonnen må være tilstede i begge DataFrame-objektene.
I argumentene "left_on" og "right_on" er "left_on" navnet på kolonnenavnet som nøkkelen i venstre DataFrame. “Right_on” er navnet på kolonnen som brukes som en nøkkel fra riktig DataFrame.
For å utdype konseptet med å bli med i DataFrames, har vi tatt to DataFrame-objekter - produkt og kunde. Følgende detaljer er tilstede i produktets DataFrame:
produkt = pd.Dataramme('Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
Kundens DataFrame inneholder følgende detaljer:
kunde = pd.Dataramme('ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'Customer_City': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
Bli med DataFrames på en nøkkel
Vi kan enkelt finne produkter som selges online og kundene som kjøpte dem. Så, basert på nøkkelen "Product_ID", har vi utført indre sammenføyningsoperasjon på begge DataFrames som følger:
# importer Pandas-biblioteketimporter pandaer som pd
produkt = pd.Dataramme(
'Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
kunde = pd.Dataramme(
'ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'By': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
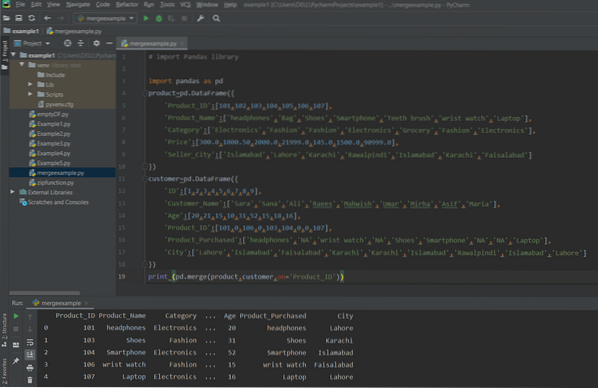
skriv ut (pd.flette (produkt, kunde, på = 'Product_ID'))
Følgende utgang vises i vinduet etter å ha kjørt ovennevnte kode:
Hvis kolonnene er forskjellige i begge DataFrames, så skriv navnet på hver kolonne eksplisitt med argumentene left_on og right_on som følger:
importer pandaer som pdprodukt = pd.Dataramme(
'Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
kunde = pd.Dataramme(
'ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'By': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
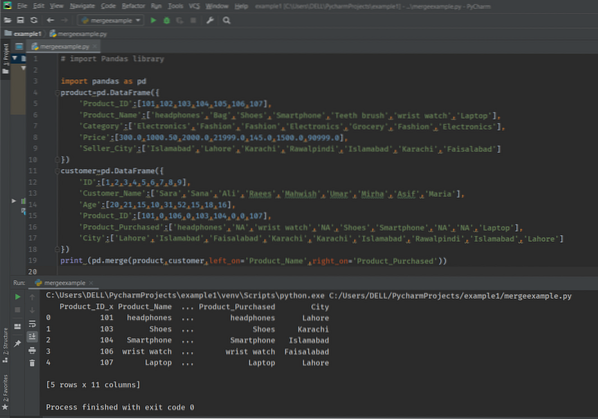
skriv ut (pd.flette (produkt, kunde, left_on = 'Product_Name', right_on = 'Product_Purchased'))
Følgende utgang vises på skjermen:
Bli med i DataFrames ved hjelp av How Argument
I de følgende eksemplene vil vi forklare fire typer Joins-operasjoner på Pandas DataFrames:
- Inner Join
- Ytre sammenføyning
- Venstre Bli med
- Right Join
Indre Bli med i Pandaer
Vi kan utføre en indre sammenføyning på flere taster. For å vise mer informasjon om produktsalget, ta Product_ID, Seller_City fra produktet DataFrame og Product_ID, og “Customer_City” fra Customer DataFrame for å finne ut at enten selger eller kunde tilhører samme by. Implementere følgende kodelinjer:
# importer Pandas-biblioteketimporter pandaer som pd
produkt = pd.Dataramme(
'Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
kunde = pd.Dataramme(
'ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'Customer_City': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
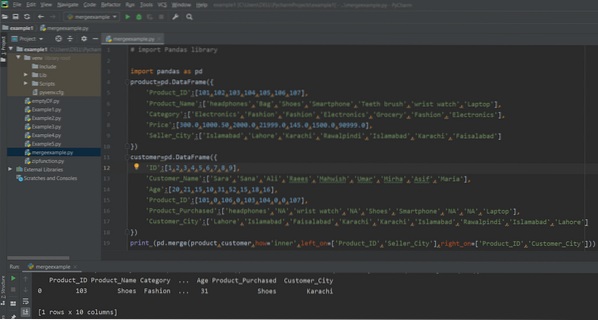
skrive ut (pd.flette (produkt, kunde, hvordan = 'indre', left_on = ['Product_ID', 'Seller_City'], right_on = ['Product_ID', 'Customer_City']))
Følgende resultat vises i vinduet etter å ha kjørt ovennevnte kode:
Full / ytre sammenføyning i Pandas
Ytre sammenføyninger returnerer både høyre og venstre DataFrames-verdier, som enten har treff. Så, for å implementere den ytre sammenføyningen, sett "hvordan" -argumentet som ytre. La oss endre eksemplet ovenfor ved å bruke det ytre sammenføyningskonseptet. I koden nedenfor returnerer den alle verdiene til både venstre og høyre DataFrames.
# importer Pandas-biblioteketimporter pandaer som pd
produkt = pd.Dataramme(
'Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
kunde = pd.Dataramme(
'ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'Customer_City': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
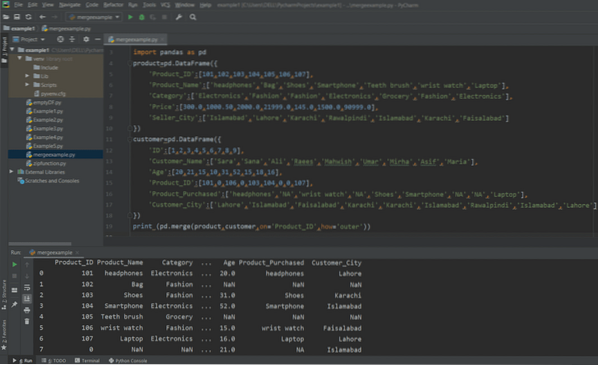
skriv ut (pd.flette (produkt, kunde, på = 'Produkt_ID', hvordan = 'ytre'))
Sett indikatorargumentet som “Sann”. Du vil legge merke til at den nye kolonnen “_merge” er lagt til på slutten.
# importer Pandas-biblioteketimporter pandaer som pd
produkt = pd.Dataramme(
'Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
kunde = pd.Dataramme(
'ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'Customer_City': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
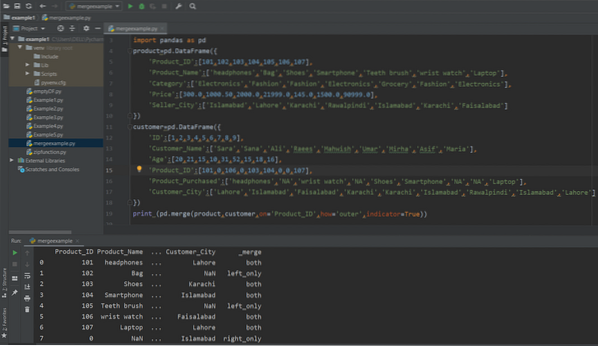
skrive ut (pd.flette (produkt, kunde, på = 'Product_ID', hvordan = 'ytre', indikator = True))
Som du kan se på skjermbildet nedenfor, forklarer verdiene for flettekolonnene hvilken rad som tilhører hvilken DataFrame.
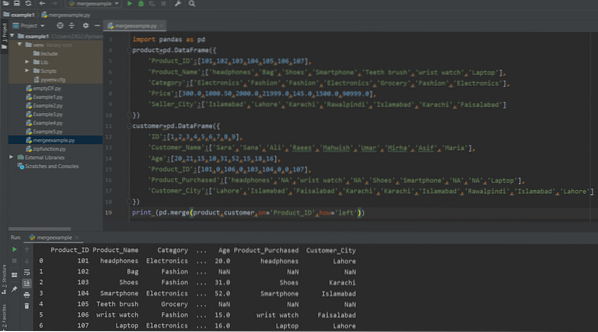
Venstre Bli med i Pandas
Venstre sammenføyning viser bare rader av venstre DataFrame. Det ligner på den ytre skjøten. Så, endre 'hvordan' argumentverdien med "venstre". Prøv følgende kode for å implementere ideen om Left join:
# importer Pandas-biblioteketimporter pandaer som pd
produkt = pd.Dataramme(
'Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
kunde = pd.Dataramme(
'ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'Customer_City': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
skrive ut (pd.flette (produkt, kunde, på = 'Product_ID', hvordan = 'venstre'))
Right Join i Pandas
Høyre sammenføyning holder alle riktige DataFrame-rader til høyre sammen med radene som også er vanlige i venstre DataFrame. I dette tilfellet settes "hvordan" -argumentet som "riktig" verdi. Kjør følgende kode for å implementere riktig sammenføyningskonsept:
# importer Pandas-biblioteketimporter pandaer som pd
produkt = pd.Dataramme(
'Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
kunde = pd.Dataramme(
'ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'Customer_City': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
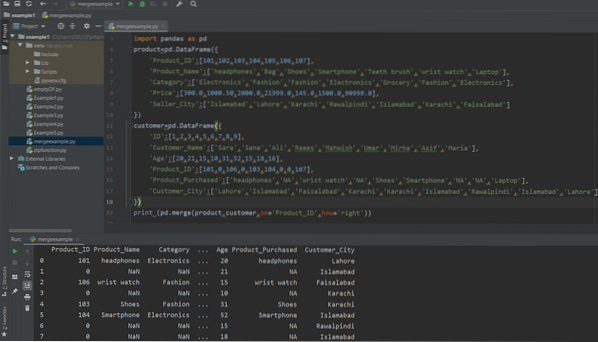
skriv ut (pd.flette (produkt, kunde, på = 'Product_ID', how = 'right'))
I det følgende skjermbildet kan du se resultatet etter å ha kjørt ovennevnte kode:
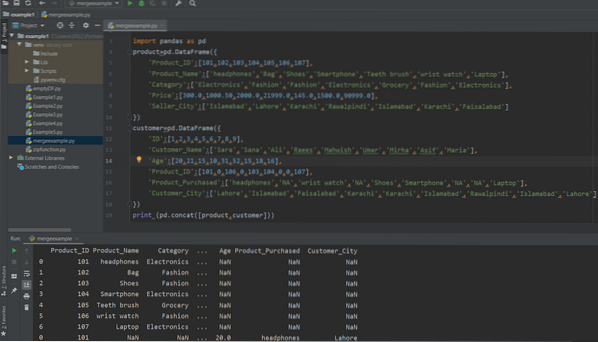
Sammenkobling av DataFrames ved hjelp av Concat () -funksjonen
To DataFrames kan settes sammen ved hjelp av concat-funksjonen. Den grunnleggende syntaksen for sammenkoblingsfunksjonen er gitt nedenfor:
pd.concat ([df_obj1, df_obj_2]))To DataFrames-objekter vil passere som argumenter.
La oss bli med både DataFrames-produktet og kunden gjennom concat-funksjonen. Kjør følgende kodelinjer for å bli med i to DataFrames:
# importer Pandas-biblioteketimporter pandaer som pd
produkt = pd.Dataramme(
'Produkt_ID': [101.102.103.104.105.106.107],
'Product_Name': ['headphones', 'Bag', 'Shoes', 'Smartphone', 'Teeth brush', 'wrist watch', 'Laptop'],
'Kategori': ['Elektronikk', 'Mote', 'Mote', 'Elektronikk', 'Dagligvarer', 'Mote', 'Elektronikk'],
'Pris': [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
'Seller_City': ['Islamabad', 'Lahore', 'Karachi', 'Rawalpindi', 'Islamabad', 'Karachi', 'Faisalabad']
)
kunde = pd.Dataramme(
'ID': [1,2,3,4,5,6,7,8,9],
'Customer_Name': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Alder': [20,21,15,10,31,52,15,18,16],
'Produkt_ID': [101,0,106,0,103,104,0,0,107],
'Product_Purchased': ['headphones', 'NA', 'wrist watch', 'NA', 'Shoes', 'Smartphone', 'NA', 'NA', 'Laptop'],
'Customer_City': ['Lahore', 'Islamabad', 'Faisalabad', 'Karachi', 'Karachi', 'Islamabad', 'Rawalpindi', 'Islamabad',
'Lahore']
)
skrive ut (pd.concat ([produkt, kunde]))
Konklusjon:
I denne artikkelen har vi diskutert implementeringen av merge () -funksjon, concat () -funksjoner, og blir med i drift i Pandas python. Ved å bruke metodene ovenfor kan du enkelt bli med i to DataFrames og lære. hvordan du implementerer Join-operasjonene “indre, ytre, venstre og høyre” i Pandas. Forhåpentligvis vil denne opplæringen veilede deg i implementering av tilknytningsoperasjoner på forskjellige typer DataFrames. Gi oss beskjed om dine vanskeligheter i tilfelle feil.


