Denne artikkelen viser deg hvordan du finner duplikater i data og fjern duplikatene ved hjelp av Pandas Python-funksjonene.
I denne artikkelen har vi tatt et datasett over befolkningen i forskjellige stater i USA, som er tilgjengelig i en .csv-filformat. Vi vil lese .csv-fil for å vise det opprinnelige innholdet i denne filen, som følger:
importer pandaer som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
skriv ut (df_state)
I det følgende skjermbildet kan du se duplikatinnholdet i denne filen:
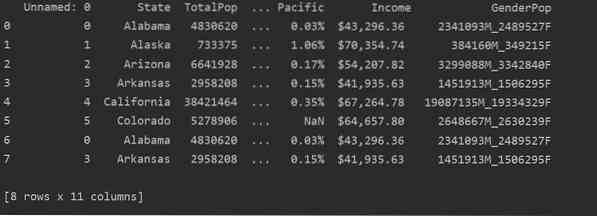
Identifisere duplikater i Pandas Python
Det er nødvendig å avgjøre om dataene du bruker har dupliserte rader. For å sjekke om dataduplisering kan du bruke en av metodene som er dekket i de følgende avsnittene.
Metode 1:
Les csv-filen og send den inn i datarammen. Identifiser deretter de dupliserte radene ved hjelp av duplisert () funksjon. Til slutt, bruk utskriftsuttalelsen for å vise dupliserte rader.
importer pandaer som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplisert ()]
skriv ut ("\ n \ nDupliser rader: \ n ".format (Dup_Rows))
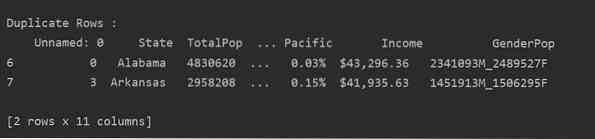
Metode 2:
Ved hjelp av denne metoden, er_duplisert kolonne vil bli lagt til på slutten av tabellen og merket som 'True' når det gjelder dupliserte rader.
importer pandaer som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
df_state ["is_duplicate"] = df_state.duplisert ()
skriv ut ("\ n ".format (df_state))
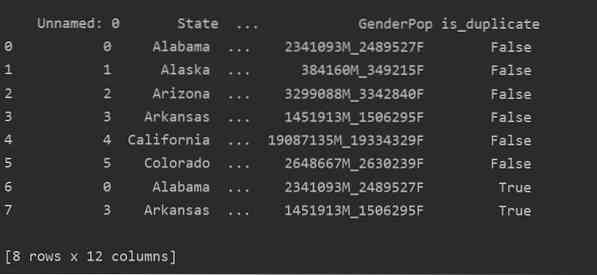
Dropping duplikater i Pandas Python
Dupliserte rader kan fjernes fra datarammen din ved hjelp av følgende syntaks:
drop_duplicates (subset = ", keep =", inplace = False)
Ovennevnte tre parametere er valgfrie og forklares nærmere nedenfor:
beholde: denne parameteren har tre forskjellige verdier: Første, Siste og Falske. Den første verdien beholder den første forekomsten og fjerner påfølgende duplikater, den siste verdien beholder bare den siste forekomsten og fjerner alle tidligere duplikater, og den falske verdien fjerner alle dupliserte rader.
delmengde: etikett som brukes til å identifisere de dupliserte radene
på plass: inneholder to forhold: Sann og usann. Denne parameteren fjerner dupliserte rader hvis den er satt til Sann.
Fjern duplikater som bare holder den første forekomsten
Når du bruker "keep = first", blir bare den første radforekomsten beholdt, og alle andre duplikater blir fjernet.
Eksempel
I dette eksemplet blir bare den første raden beholdt, og de resterende duplikatene blir slettet:
importer pandaer som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplisert ()]
skriv ut ("\ n \ nDupliser rader: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = 'first')
skriv ut ('\ n \ nResult DataFrame etter duplikatfjerning: \ n', DF_RM_DUP.hode (n = 5))
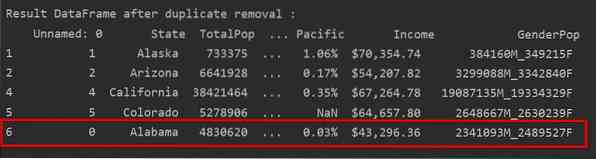
I det følgende skjermbildet er den beholdte første radforekomsten uthevet i rødt og de gjenværende duplikasjonene fjernes:
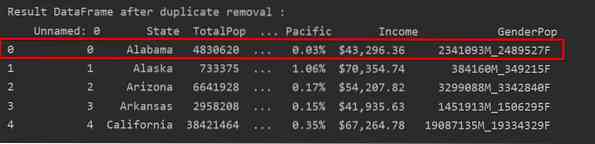
Fjern duplikater som bare holder den siste forekomsten
Når du bruker "keep = last", blir alle dupliserte rader unntatt den siste forekomsten fjernet.
Eksempel
I det følgende eksemplet fjernes alle dupliserte rader, bortsett fra bare den siste forekomsten.
importer pandaer som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplisert ()]
skriv ut ("\ n \ nDupliser rader: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = 'last')
skriv ut ('\ n \ nResult DataFrame etter duplikatfjerning: \ n', DF_RM_DUP.hode (n = 5))
I det følgende bildet fjernes duplikatene, og bare den siste radforekomsten beholdes:
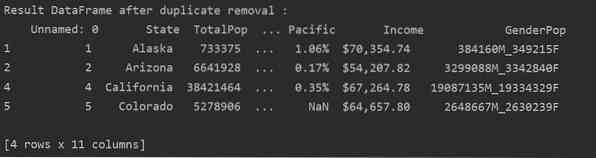
Fjern alle dupliserte rader
For å fjerne alle dupliserte rader fra en tabell, sett "keep = False", som følger:
importer pandaer som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplisert ()]
skriv ut ("\ n \ nDupliser rader: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = False)
skriv ut ('\ n \ nResult DataFrame etter duplikatfjerning: \ n', DF_RM_DUP.hode (n = 5))
Som du kan se i det følgende bildet, fjernes alle duplikater fra datarammen:
Fjern relaterte duplikater fra en spesifisert kolonne
Som standard sjekker funksjonen for alle dupliserte rader fra alle kolonnene i den gitte datarammen. Men du kan også spesifisere kolonnenavnet ved å bruke delsettparameteren.
Eksempel
I det følgende eksemplet fjernes alle relaterte duplikater fra kolonnen 'Stater'.
importer pandaer som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplisert ()]
skriv ut ("\ n \ nDupliser rader: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (subset = 'State')
skriv ut ('\ n \ nResult DataFrame etter duplikatfjerning: \ n', DF_RM_DUP.hode (n = 6))
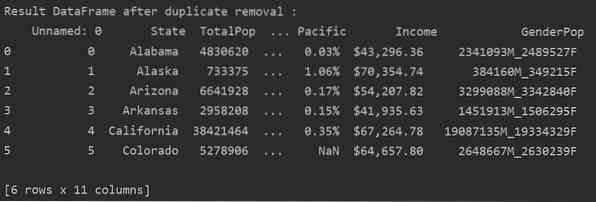
Konklusjon
Denne artikkelen viste deg hvordan du fjerner dupliserte rader fra en dataramme ved hjelp av drop_duplicates () funksjon i Pandas Python. Du kan også fjerne dataene for duplisering eller redundans ved hjelp av denne funksjonen. Artikkelen viste deg også hvordan du identifiserer duplikater i datarammen.


