Funksjonen til grep er å søke i teksten og bruke vilkår for dem. Den brukes til å søke i mer enn en fil. Grep kan identifisere tekstlinjene i den og bestemme seg videre for å bruke forskjellige handlinger som inkluderer rekursiv funksjon eller omvendt søket og vise linjenummeret som utdata osv. Spesialtegn er de vanlige uttrykkene som brukes i kommandoer for å utføre flere handlinger som #,%, *, &, $, @, etc. I denne artikkelen vil vi bruke spesialtegn. Grep tillater argumentene som strenger som er spesifisert som et regulært uttrykk. Det har også muligheten til å erstatte et ord eller en setning i det. Spesialtegn brukes ikke bare som filnavn, men også som data som finnes i filen.
Forutsetning
For å utføre det, må vi ha Linux-operativsystemet. For at Linux skal kunne kjøre, må vi ha en virtuell boks forhåndsinstallert. Etter vellykket installasjon av Linux, vil du konfigurere den ved å gi litt nyttig informasjon. Neste trinn er å gå inn på Ubuntu Linux hjemmeside. Ved å oppgi brukernavn og passord, vil du kunne få tilgang til alle applikasjoner -typectrl + alt + t for å åpne terminalen.
Bruke “$”
For å forstå begrepet “$” spesialtegnet i grep-kommandoen, må du ha en fil som heter file21.tekst. “$” Brukes til å vise alle linjene som har et tegn definert bak “$” som er et semikolon, dvs.e., '; $'. Vi kan vise alt relevant innhold ved hjelp av kattkommandoen.
$ Cat-fil21.tekst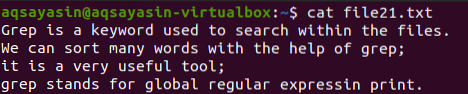
Nå skal vi bruke tegnet i følgende kommando for å forstå hvordan det fungerer. “-E” hjelper med å vise nøyaktig samsvar i filen.
$ grep -e '; $' fil21.tekst
Ovennevnte utgang viser alle linjene i filen som har semikolon ";" på slutten. Det respektive resultatet er fremhevet mot hver linje.
Ved hjelp av"
Dette er et enkelt eksempel på et vanlig uttrykk. I alle grep-setninger brukes enkelt anførselstegn når vi vil matche et hvilket som helst ord i en fil. På samme måte har vi nevnt dette eksemplet for å gjøre det presist og ganske forståelig for brukeren.
$ grep -e 'Aqsa' fil23.tekstUtgangen vil inneholde alle setningene som inneholder ordet Aqsa i det siden vi søkte dette ordet i kommandoen.

Ved hjelp av []
Firkantede parenteser brukes til å nevne ordet som skal søkes mellom de to parene med parentes. Disse firkantede parentesene blir fulgt av "*" i kommandoen. Videre har vi brukt -n -I -w -e i kommandoen for å få utdataene med linjenummeret nøyaktig, ignorere saksfølsomhet, og få den nøyaktige samsvaren som har skjedd mer enn en gang i en fil. Vi skal bruke en fil fileg.txt for å vise dataene som er tilstede i den. -E brukes som et utvidet regulært uttrykk når vi bruker et tegn i kommandoen.
$ Cat fileg.tekst
Vi vil nå bruke følgende spørsmål.
$ grep -noiwe -e '[] * the [] *' fileg.tekst
Hvor fileg.txt er en bekymret fil. Utgangen viser ordet “the” hvor det er i filen sammen med linjenummeret. Bare ordet vises, men ikke hele setningen fordi vi har brukt -w og -e for å vise forekomsten og vise nøyaktighet.
Ved hjelp av '-'
'-' brukes i kommandoen for å finne et samsvar i filen. -niw representerer igjen den samme betydningen som beskrevet i eksemplet nevnt ovenfor. -m viser den første linjen som inneholder ordet i den eksisterende filen.
$ grep -nye -m 3 'teknisk' fil 1.tekst
Utgangen viser linjene som inneholder ordet teknisk. Linjenummeret som har ordet 'teknisk' vises også som er i 1 og 4.
Bruke “|”
Denne spesielle karakteren brukes på mange måter. Generelt brukes den som OR-operatør for å velge mellom de to fornavnene. I en grep-kommando brukes den til å fungere slik at den henter posten til enten ett eller begge ord atskilt med “|”. Her viser eksemplet henting av to ord som er tilstede i alle filene i katalogen.
$ grep -I -E -w 'Aqsa | bra' / hjem / aqsayasin / fil *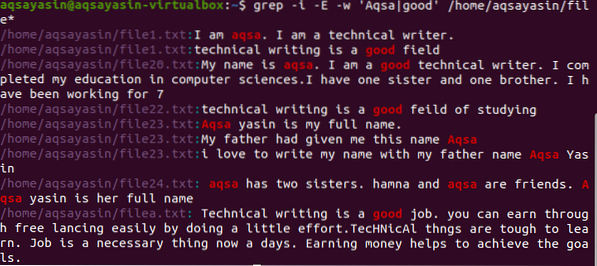
Nå viser utgangen begge ordene til stede enten i en enkelt fil eller forskjellige filer. Som vi har nevnt i katalogen, vil vi også få filnavn.
Bruke '^ ()'
Her fungerer '^ ()' rekursivt sammenlignet med eksemplet ovenfor.“^” Viser bare ett av de to gitte alternativene, i.e., Aqsa og bra, det kommer først i alle filer. Utdataene inneholder bare Aqsa. Egrep er et utvidet regulært uttrykk.
$ egrep -I '^ (aqsa | bra)' / home / aqsayasin / *.tekst
Bruker ^ $
Den viser matching av tomme / tomme strenger på slutten av en linje. Hvis det er noe gap i teksten, blir det hentet av følgende kommando.
$ grep -n '^ $' / home / aqsayasin / *.tekst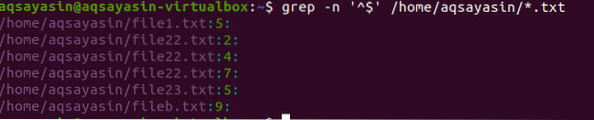
Det vil bli søkt i alle tekstfiler. Utgangen vil inneholde filnavn og også linjenummeret som inneholder den tomme plassen i filen. Vi har brukt -n i kommandoen.

Ved hjelp av []
Disse to parentesene viser hvordan spesialtegn fungerer. [] inneholder ordet som skal søkes. På samme tid beskriv samsvaret i filen N ganger. I det videre eksemplet har vi brukt 2, som viser forekomsten av alle to mulige ord for det angitte ordet i kommandoen som er "the".
$ egrep '[the] 2' / home / aqsayasin / file *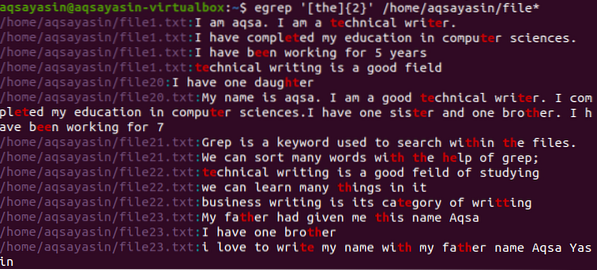
Konklusjon
I artikkelen som nevnt tidligere har vi diskutert noen grunnleggende eksempler for å forklare begrepet spesialtegn i en kommando. Vi opprettet filen og hentet deretter dataene som er tilstede i den ved hjelp av grep-kommandoen. Jeg håper du etter å ha lest denne artikkelen vil bli kjent med spesialtegnene vi har brukt i artikkelen vår.


