Syntaks
Grep [mønster] [filnavn]
Etter bruk av grep kommer det et mønster. Mønsteret innebærer måten vi vil bruke det til å fjerne ekstra plass i dataene. Etter mønsteret blir filnavnet beskrevet gjennom hvilket mønsteret utføres.
Forutsetning
For å forstå nytten av grep enkelt, må vi ha Ubuntu installert på systemet vårt. Gi brukerinformasjon ved å oppgi brukernavn og passord for å ha rettigheter til å få tilgang til applikasjonene til Linux. Etter at du har logget inn, åpner du applikasjonen og søker etter en terminal eller bruker hurtigtasten til ctrl + alt + T.
Ved å bruke [: blank:] Keyword
Anta at vi har en fil som heter bfile som har en tekstutvidelse. Du kan opprette en fil enten i tekstredigerer eller med en kommandolinje i terminalen. Å lage en fil på terminalen, inkludert følgende kommandoer.
$ Echo "tekst som skal legges inn i en fil"> filnavn.tekstDet er ikke nødvendig å opprette en fil hvis den allerede er til stede. Bare vis det ved hjelp av den vedlagte kommandoen:
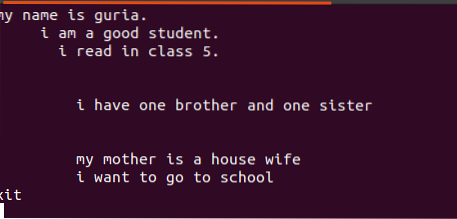
$ echo filnavn.tekstTekst skrevet i disse filene inneholder mellomrom mellom dem, som vist i figuren nedenfor.
![]()
Disse tomme linjene kan fjernes ved å bruke en tom kommando for å ignorere tomme mellomrom mellom ordene eller strengene.
$ egrep '^ [[: blank]] * [^ [: blank:] #]' bfil.tekst![]()
Etter at spørringen er brukt, blir de tomme mellomromene mellom linjene fjernet, og utdataene vil ikke lenger inneholde ekstra plass. Det første ordet er uthevet som mellomrom mellom det siste ordet på linjen og mellom de første ordene i neste linje fjernes. Vi kan også bruke betingelser på den samme grep-kommandoen ved å legge til denne tomme funksjonen for å fjerne ubrukelig plass i utgangen.
Ved å bruke [: space:]
Et annet eksempel på å ignorere rom forklares her.
Uten å nevne filtypen, vil vi først vise den eksisterende filen ved hjelp av kommandoen.
$ kattfil20![]()
La oss se på hvordan ekstra plass fjernes ved hjelp av grep-kommandoen i tillegg til nøkkelordet [: space:]. Greps alternativ -v hjelper med å skrive ut linjer som mangler blanke linjer og ekstra avstand som også er inkludert i avsnittform.
$ grep -v '^ [[; space:]] * $' file20Du vil se at ekstra linjer fjernes og utdata er i sekvensert form linjemessig. Slik er grep -v metodikk så nyttig for å oppnå det nødvendige målet.
![]()
Nevnende filutvidelser begrenser grep-funksjonaliteten til å bare utføre på de bestemte filtypene, dvs.e., .tekst eller .mp3. Når vi utfører en justering av en tekstfil, tar vi fileg.txt som en eksempelfil. Først vil vi vise teksten som er tilstede i den ved hjelp av $ cat-funksjonen. Resultatet er som følger:
![]()
Ved å bruke kommandoen er utdatafilen vår oppnådd. Her kan vi se data uten avstand mellom linjene som skrives fortløpende.
$ grep -v '^ [[: space:]] * $' fileg.tekst![]()
Foruten lange kommandoer, kan vi også gå med de korte skriftlige kommandoene i Linux og Unix for å implementere grep støtter stenografiske tegn i den.
$ grep 's' filnavn.tekstVi har sett hvordan produksjonen oppnås ved å bruke kommandoer fra inngangen. Her vil vi lære hvordan input holdes tilbake fra output.
$ grep '\ S' filnavn.txt> tmp.txt && mv tmp.txt filnavn.tekstHer vil vi bruke en midlertidig tekstfil med utvidelse av tekst som heter tmp.
Ved å bruke ^ #
Akkurat som andre eksempler som er beskrevet, vil vi bruke kommandoen på tekstfilen ved hjelp av cat-kommandoen. Vi kan også vise tekst ved hjelp av ekkokommandoen.
$ echo filnavn.tekstTekstfilen inneholder fire linjer, med mellomrom mellom dem. Disse mellomromslinjene fjernes enkelt ved hjelp av en bestemt kommando.
![]()
Regelmessige utvidede operasjoner er aktivert av -E, som tillater alle vanlige uttrykk, spesielt rør. Et rør brukes som en valgfri “eller” tilstand i ethvert mønster.”^ #”. Dette viser samsvarende tekstlinjer i filen som begynner med tegnet #. “^ $” Vil samsvare med alle ledige mellomrom i teksten eller de tomme linjene.
![]()
Utgangen viser fullstendig fjerning av ekstra mellomrom mellom linjene i datafilen. I dette eksemplet har vi sett at i kommandoen at ”^ #” kommer først, noe som betyr at teksten matches først. “^ $” Kommer etter | operatøren, så ledig plass blir matchet etterpå.
Ved å bruke ^ $
Akkurat som eksemplet nevnt ovenfor, kommer vi med de samme resultatene fordi kommandoen er nesten den samme. Mønsteret er imidlertid skrevet motsatt. Fil22.txt er en fil som vi skal bruke til å fjerne mellomrom.
![]()
Den samme metoden brukes, bortsett fra å jobbe med prioritet. I følge denne kommandoen vil først ledige mellomrom bli matchet, deretter blir tekstfilene matchet. Utgangen vil gi en rekke linjer ved å fjerne ekstra hull i dem.
![]()
Andre enkle kommandoer
- Grep '^ ...' filnavn.
- Grep '.' Filnavn
Disse begge er så enkle og hjelper til med å fjerne hull i tekstlinjer.
Konklusjon
Fjerne unyttige hull i filer ved hjelp av vanlige uttrykk er ganske enkel tilnærming for å oppnå en jevn sekvens av data og opprettholde konsistens. Eksempler blir forklart på en detaljert måte for å forbedre informasjonen din om emnet.


