Når vi snakker om distribuerte systemer som ovenfor, støter vi på problemet med analyse og overvåking. Hver node genererer mye informasjon om sin egen helse (CPU-bruk, minne osv.) Og om applikasjonsstatus sammen med hva brukerne prøver å gjøre. Disse detaljene må registreres i:
- Den samme rekkefølgen de er opprettet i,
- Separert når det gjelder haster (sanntidsanalyser eller batcher av data), og viktigst av alt,
- Mekanismen som de samles med må i seg selv være distribuert og skalerbar, ellers sitter vi igjen med et eneste feilpunkt. Noe den distribuerte systemdesignen skulle unngå.
Hvorfor bruke Kafka?
Apache Kafka presenteres som en distribuert streamingsplattform. I Kafka lingo, Produsenter kontinuerlig generere data (bekker) og Forbrukere er ansvarlig for behandling, lagring og analyse. Kafka Meglere er ansvarlig for at dataene i et distribuert scenario kan nå fra produsenter til forbrukere uten inkonsekvens. Et sett med Kafka-meglere og en annen programvare som heter dyrepasser utgjør en typisk Kafka-distribusjon.
Datastrømmen fra mange produsenter må samles, partisjoneres og sendes til flere forbrukere, det er mye blanding involvert. Å unngå inkonsekvens er ikke en enkel oppgave. Dette er grunnen til at vi trenger Kafka.
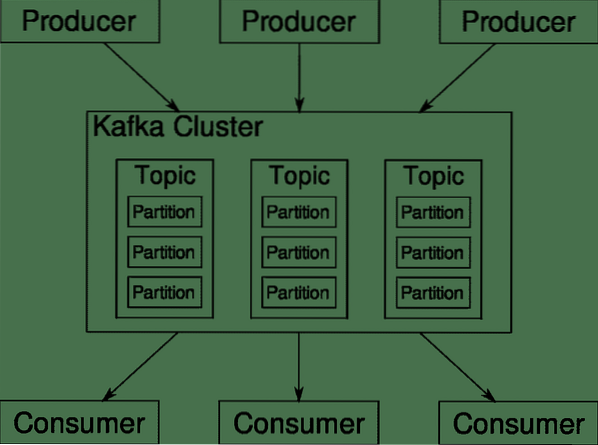
Scenariene der Kafka kan brukes er ganske forskjellige. Alt fra IOT-enheter til klyngen av virtuelle maskiner til dine egne lokale metal-servere. Hvor som helst hvor mange "ting" samtidig vil ha oppmerksomhet .. .Det er ikke veldig vitenskapelig? Vel, Kafka-arkitekturen er et eget kaninhull og fortjener en uavhengig behandling. La oss først se en veldig overflatenivå distribusjon av programvaren.
Bruke Docker Compose
Uansett hvilken fantasifull måte du bestemmer deg for å bruke Kafka, er en ting sikker - du vil ikke bruke den som en eneste forekomst. Det er ikke ment å brukes på den måten, og selv om den distribuerte appen din bare trenger en forekomst (megler) for nå, vil den til slutt vokse, og du må sørge for at Kafka kan følge med.
Docker-compose er den perfekte partneren for denne typen skalerbarhet. I stedet for å kjøre Kafka-meglere på forskjellige virtuelle maskiner, containeriserer vi det og utnytter Docker Compose for å automatisere distribusjon og skalering. Docker-containere er svært skalerbare på begge enkelt-Docker-verter så vel som på tvers av en klynge hvis vi bruker Docker Swarm eller Kubernetes. Så det er fornuftig å utnytte det for å gjøre Kafka skalerbar.
La oss starte med en enkelt meglerforekomst. Lag en katalog som heter apache-kafka, og opprett docker-compose i den.yml.
$ mkdir apache-kafka$ cd apache-kafka
$ vim docker-compose.yml
Følgende innhold kommer til å legges i din docker-compose.yml-fil:
versjon: '3'tjenester:
dyrepasser:
bilde: wurstmeister / zooeeper
kafka:
bilde: wurstmeister / kafka
porter:
- "9092: 9092"
miljø:
KAFKA_ADVERTISED_HOST_NAME: lokal vert
KAFKA_ZOOKEEPER_CONNECT: dyrehage: 2181
Når du har lagret innholdet ovenfor i komponentfilen din, fra samme katalogkjøring:
$ docker-compose up -dOk, så hva gjorde vi her?
Forstå Docker-Compose.yml
Compose starter to tjenester som er oppført i yml-filen. La oss se litt nøye på filen. Det første bildet er dyrehage som Kafka trenger for å holde oversikt over forskjellige meglere, nettverkstopologien samt synkronisere annen informasjon. Siden både dyrehage- og kafka-tjenester kommer til å være en del av det samme bronettverket (dette opprettes når vi kjører docker-compose up), trenger vi ikke å eksponere noen porter. Kafka-megler kan snakke med dyrehage og det er all kommunikasjon som dyrehage trenger.
Den andre tjenesten er kafka i seg selv, og vi kjører bare en enkelt forekomst av den, det vil si en megler. Ideelt sett vil du bruke flere meglere for å utnytte den distribuerte arkitekturen til Kafka. Tjenesten lytter på port 9092 som er kartlagt på samme portnummer på Docker Host, og det er slik tjenesten kommuniserer med omverdenen.
Den andre tjenesten har også et par miljøvariabler. Først er KAFKA_ADVERTISED_HOST_NAME satt til lokal vert. Dette er adressen Kafka kjører på, og hvor produsenter og forbrukere kan finne den. Nok en gang, dette bør være satt til localhost, men heller til IP-adressen eller vertsnavnet med dette, serverne kan nås i nettverket ditt. For det andre er vertsnavnet og portnummeret til dyrepasser-tjenesten din. Siden vi kalte dyrehage-tjenesten ... vel, dyrehage er det hva vertsnavnet kommer til å være, innenfor docker bridge-nettverket vi nevnte.
Kjører en enkel meldingsflyt
For at Kafka skal begynne å jobbe, må vi lage et emne innenfor det. Produsentklientene kan deretter publisere datastrømmer (meldinger) til nevnte emne, og forbrukerne kan lese nevnte datastrøm, hvis de abonnerer på det aktuelle emnet.
For å gjøre dette må vi starte en interaktiv terminal med Kafka-containeren. Oppgi beholderne for å hente navnet på kafka-containeren. I dette tilfellet heter for eksempel containeren vår apache-kafka_kafka_1
$ docker psMed kafka containerens navn kan vi nå falle inne i denne containeren.
$ docker exec -it apache-kafka_kafka_1 bashbash-4.4 #
Åpne to slike forskjellige terminaler for å bruke en som forbruker og en annen produsent.
Produsentens side
Skriv inn følgende kommandoer i en av instruksjonene (den du velger å være produsent):
## For å lage et nytt emne som heter testbash-4.4 # kafka-topics.sh --create - zookeeper zookeeper: 2181 - replikasjonsfaktor 1
--partisjoner 1 - emnetest
## Å starte en produsent som publiserer datastrøm fra standardinngang til kafka
bash-4.4 # kafka-konsoll-produsent.sh - meglerliste localhost: 9092 - emnetest
>
Produsenten er nå klar til å ta innspill fra tastaturet og publisere det.
Forbrukerens side
Gå videre til den andre terminalen som er koblet til kafka-containeren. Følgende kommando starter en forbruker som lever av testemne:
$ kafka-konsoll-forbruker.sh --bootstrap-server localhost: 9092 --topatestTilbake til produsent
Du kan nå skrive meldinger i den nye ledeteksten, og hver gang du trykker på retur, blir den nye linjen skrevet ut i forbrukerleddet. For eksempel:
> Dette er en melding.Denne meldingen blir overført til forbrukeren gjennom Kafka, og du kan se den skrives ut ved forbrukerprompten.
Virkelige oppsett
Du har nå et grovt bilde av hvordan Kafka-oppsettet fungerer. For ditt eget bruk, må du angi et vertsnavn som ikke er localhost, du trenger flere slike meglere for å være en del av kafka-klyngen din, og til slutt må du konfigurere forbruker- og produsentklienter.
Her er noen nyttige lenker:
- Confluents Python Client
- Offisiell dokumentasjon
- En nyttig liste over demoer
Jeg håper du har det gøy med å utforske Apache Kafka.


