Denne oversikten er litt abstrakt, så la oss grunnlegge den i et virkelig scenario, tenk at du trenger å overvåke flere webservere. Hver driver sitt eget nettsted, og nye logger blir kontinuerlig generert i hver av dem hvert sekund av dagen. På toppen av det er det en rekke e-postservere du også må overvåke.
Det kan hende du må lagre disse dataene for journalføring og fakturering, noe som er en batchjobb som ikke krever umiddelbar oppmerksomhet. Det kan være lurt å kjøre analyser på dataene for å ta avgjørelser i sanntid, noe som krever nøyaktig og øyeblikkelig innspill av data. Plutselig befinner du deg i behovet for å effektivisere dataene på en fornuftig måte for alle de forskjellige behovene. Kafka fungerer som det abstraksjonslaget som flere kilder kan publisere forskjellige datastrømmer og en gitt forbruker kan abonnere på strømmen den finner relevant. Kafka vil sørge for at dataene er ordnet. Det er det indre av Kafka som vi trenger å forstå før vi kommer til temaet Partisjonering og nøkler.
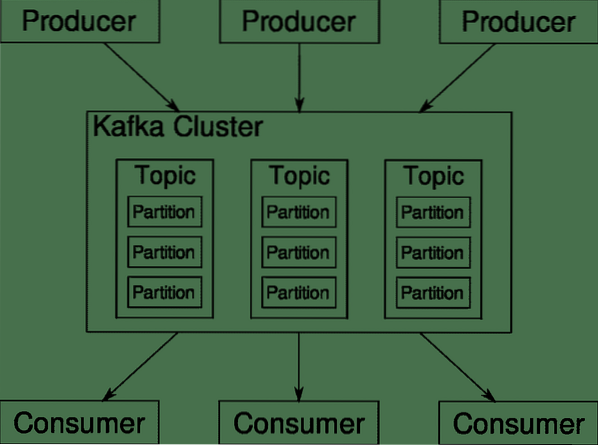
Kafka Emner, megler og partisjoner
Kafka Temaer er som tabeller i en database. Hvert emne består av data fra en bestemt kilde av en bestemt type. For eksempel kan klyngens helse være et tema som består av informasjon om CPU og minneutnyttelse. På samme måte kan innkommende trafikk til klyngen være et annet tema.
Kafka er designet for å være skalerbar horisontalt. Det vil si at en enkelt forekomst av Kafka består av flere Kafka meglere kjører over flere noder, kan hver håndtere datastrømmer parallelt med den andre. Selv om noen av nodene mislykkes, kan datarørledningen fortsette å fungere. Et bestemt emne kan deretter deles inn i et antall skillevegger. Denne partisjoneringen er en av de avgjørende faktorene bak den horisontale skalerbarheten til Kafka.
Flere produsenter, datakilder for et gitt emne, kan skrive til det emnet samtidig fordi hver skriver til en annen partisjon, til enhver tid. Nå tildeles vanligvis data tilfeldig til en partisjon, med mindre vi gir den en nøkkel.
Partisjonering og bestilling
Bare for å oppsummere skriver produsenter data til et gitt emne. Dette emnet er faktisk delt inn i flere partisjoner. Og hver partisjon lever uavhengig av de andre, selv for et gitt emne. Dette kan føre til mye forvirring når bestillingen til data betyr noe. Kanskje du trenger dataene dine i en kronologisk rekkefølge, men å ha flere partisjoner for datastrømmen din garanterer ikke perfekt bestilling.
Du kan bare bruke en enkelt partisjon per emne, men det ødelegger hele formålet med Kafkas distribuerte arkitektur. Så vi trenger en annen løsning.
Nøkler for partisjoner
Data fra en produsent sendes tilfeldig til partisjoner, som vi nevnte tidligere. Meldinger er de faktiske biter av data. Hva produsenter kan gjøre i tillegg til bare å sende meldinger, er å legge til en nøkkel som følger med den.
Alle meldingene som kommer med den spesifikke nøkkelen vil gå til samme partisjon. Så for eksempel kan en brukers aktivitet spores kronologisk hvis brukerens data er merket med en nøkkel, og slik at de alltid ender i en partisjon. La oss kalle denne partisjonen p0 og brukeren u0.
Partisjon p0 vil alltid hente de u0-relaterte meldingene fordi den nøkkelen binder dem sammen. Men det betyr ikke at p0 bare er bundet opp med det. Det kan også ta opp meldinger fra u1 og u2 hvis den har kapasitet til det. På samme måte kan andre partisjoner konsumere data fra andre brukere.
Poenget at dataene til en gitt bruker ikke er spredt over forskjellige partisjoner, noe som sikrer kronologisk rekkefølge for brukeren. Imidlertid er det overordnede temaet for brukerdata, kan fortsatt utnytte den distribuerte arkitekturen til Apache Kafka.
Konklusjon
Mens distribuerte systemer som Kafka løser eldre problemer som mangel på skalerbarhet eller å ha et eneste feilpunkt. De kommer med et sett med problemer som er unike for deres eget design. Å forutse disse problemene er en viktig jobb for enhver systemarkitekt. Ikke bare det, noen ganger må du virkelig gjøre en kostnads-nytte-analyse for å avgjøre om de nye problemene er en verdig avveining for å bli kvitt de eldre. Bestilling og synkronisering er bare toppen av isfjellet.
Forhåpentligvis kan artikler som disse og den offisielle dokumentasjonen hjelpe deg underveis.


