Apache Kafka
For en definisjon på høyt nivå, la oss presentere en kort definisjon for Apache Kafka:
Apache Kafka er en distribuert, feiltolerant, horisontalt skalerbar, logg.
Det var noen ord på høyt nivå om Apache Kafka. La oss forstå konseptene i detalj her.
- Distribuert: Kafka deler dataene den inneholder i flere servere, og hver av disse serverne er i stand til å håndtere forespørsler fra klienter om andelen data den inneholder
- Feiltolerant: Kafka har ikke et eneste feilpunkt. I et SPoF-system, som en MySQL-database, blir applikasjonen skrudd hvis serveren som er vert for databasen. I et system som ikke har en SPoF og består av flere noder, selv om det meste av systemet går ned, er det fortsatt det samme for en sluttbruker.
- Horisontalt skalerbar: Denne typen scailing refererer til å legge til flere maskiner i eksisterende klynge. Dette betyr at Apache Kafka er i stand til å akseptere flere noder i klyngen og ikke gi nedetid for nødvendige oppgraderinger til systemet. Se på bildet nedenfor for å forstå typen skrapende konsepter:
- Forpliktelseslogg: En kommitteringslogg er en datastruktur akkurat som en koblet liste. Den legger til hvilke meldinger som kommer til den og opprettholder alltid bestillingen. Data kan ikke slettes fra denne loggen før en angitt tid er nådd for disse dataene.
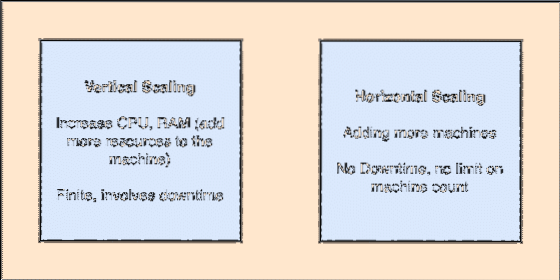
Vertikal og horisontal scailing
Et emne i Apache Kafka er akkurat som en kø der meldinger lagres. Disse meldingene lagres i en konfigurerbar tid og meldingen blir ikke slettet før denne tiden er oppnådd, selv om den har blitt fortært av alle kjente forbrukere.
Kafka er skalerbart, ettersom det er forbrukerne som faktisk lagrer at det budskapet som ble hentet av dem sist som en "offset" -verdi. La oss se på en figur for å forstå dette bedre: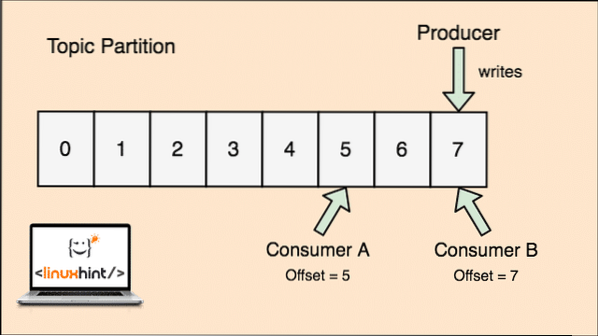
Emnedeling og forbrukerforskyvning i Apache Kafka
Komme i gang med Apache Kafka
For å begynne å bruke Apache Kafka, må den være installert på maskinen. For å gjøre dette, les Installer Apache Kafka på Ubuntu.
Forsikre deg om at du har en aktiv Kafka-installasjon hvis du vil prøve eksempler vi presenterer senere i leksjonen.
Hvordan virker det?
Med Kafka, den Produsent applikasjoner publiserer meldinger som ankommer en Kafka Node og ikke direkte til en forbruker. Fra denne Kafka-node forbrukes meldinger av Forbruker applikasjoner.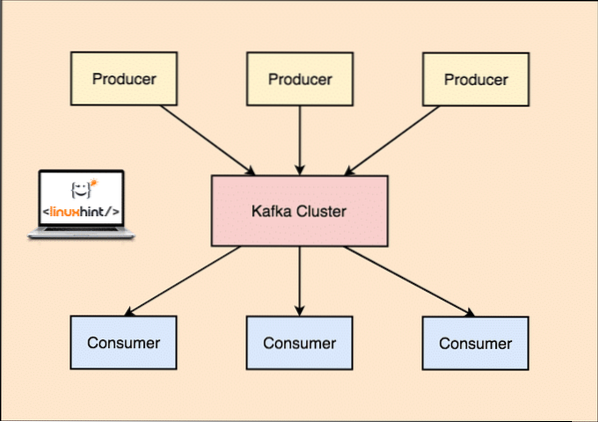
Kafka produsent og forbruker
Ettersom et enkelt emne kan få mye data på en gang, for å holde Kafka horisontalt skalerbar, er hvert emne delt inn i skillevegger og hver partisjon kan leve på hvilken som helst node-maskin i en klynge. La oss prøve å presentere det:
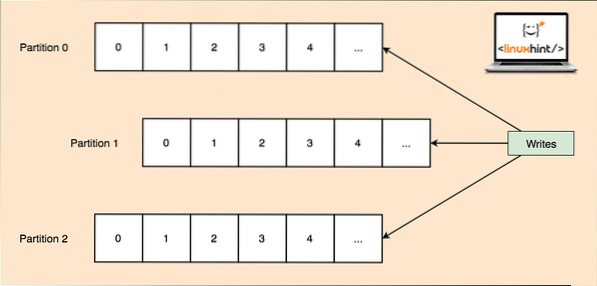
Emnepartisjoner
Igjen holder Kafka Broker ikke oversikt over hvilken forbruker som har konsumert hvor mange pakker med data. Det er den forbrukernes ansvar for å holde oversikt over data den har brukt.
Persistence to Disk
Kafka fortsetter meldingsregistrene den får fra produsenter på disken og holder dem ikke i minnet. Et spørsmål som kan oppstå er hvordan dette gjør ting mulig og raskt? Det var flere grunner bak dette som gjør det til en optimal måte å administrere meldingsoppføringene på:
- Kafka følger en protokoll for gruppering av meldingsregistrene. Produsenter produserer meldinger som er vedvarende til disk i store biter, og forbrukere bruker også disse meldingspostene i store lineære biter.
- Årsaken til at disken skriver er lineær, er at dette gjør lesing raskt på grunn av sterkt redusert lineær disklesetid.
- Lineære diskoperasjoner er optimalisert av Operativsystemer i tillegg til å bruke teknikker for skrive-bak og lese-foran.
- Moderne OS bruker også begrepet Sidecaching som betyr at de cache noen diskdata i ledig tilgjengelig RAM.
- Ettersom Kafka fortsetter data i en enhetlig standarddata i hele strømmen fra produsent til forbruker, benytter den seg av nullkopi-optimalisering prosess.
Datadistribusjon og replikering
Som vi studerte ovenfor at et emne er delt inn i partisjoner, replikeres hver meldingspost på flere noder i klyngen for å opprettholde rekkefølgen og dataene til hver post i tilfelle en av noden dør.
Selv om en partisjon er replikert på flere noder, er det fortsatt en partisjon leder node gjennom hvilken applikasjoner leser og skriver data om emnet, og lederen replikerer data på andre noder, som kalles tilhengere av den partisjonen.
Hvis meldingsregistreringsdataene er svært viktige for en applikasjon, kan garantien for at meldingsposten er trygg i en av nodene økes ved å øke replikasjonsfaktor av klyngen.
Hva er Zookeeper?
Zookeeper er en veldig feiltolerant, distribuert butikk med nøkkelverdi. Apache Kafka er sterkt avhengig av Zookeeper for å lagre klyngemekanikk som hjerterytme, distribuere oppdateringer / konfigurasjoner osv.).
Det gjør det mulig for Kafka-meglerne å abonnere på seg selv og vite når noen endringer angående en partisjonsleder og nodedistribusjon har skjedd.
Produsent- og forbrukerapplikasjoner kommuniserer direkte med Zookeeper applikasjon for å vite hvilken node som er partisjonsleder for et emne, slik at de kan utføre leser og skriver fra partisjonslederen.
Streaming
En strømprosessor er en hovedkomponent i en Kafka-klynge som tar en kontinuerlig strøm av meldingsregistreringsdata fra inndataemner, behandler disse dataene og oppretter en datastrøm til utdataemner som kan være hva som helst, fra søppel til en database.
Det er fullt mulig å utføre enkel behandling direkte ved hjelp av produsent / forbruker-API-er, men for kompleks behandling som å kombinere strømmer, tilbyr Kafka et integrert Streams API-bibliotek, men vær oppmerksom på at dette API er ment å brukes i vår egen kodebase, og det gjør det ikke ' ikke kjøre på megler. Det fungerer på samme måte som forbruker-API og hjelper oss med å skalere strømbehandlingsarbeidet over flere applikasjoner.
Når skal du bruke Apache Kafka?
Som vi studerte i avsnittene ovenfor, kan Apache Kafka brukes til å håndtere et stort antall meldingsposter som kan tilhøre et nesten uendelig antall emner i systemene våre.
Apache Kafka er en ideell kandidat når det gjelder å bruke en tjeneste som kan tillate oss å følge hendelsesdrevet arkitektur i våre applikasjoner. Dette er på grunn av dets evner til datapresistens, feiltolerant og høyt distribuert arkitektur der kritiske applikasjoner kan stole på ytelsen.
Den skalerbare og distribuerte arkitekturen til Kafka gjør integrering med mikrotjenester veldig enkelt og gjør det mulig for en applikasjon å koble seg fra seg med mye forretningslogikk.
Opprette et nytt emne
Vi kan lage et testemne testing på Apache Kafka-server med følgende kommando:
Opprette et emne
sudo kafka-emner.sh --create - zookeeper localhost: 2181 - replikasjonsfaktor 1--partisjoner 1 - emnetesting
Her er hva vi kommer tilbake med denne kommandoen: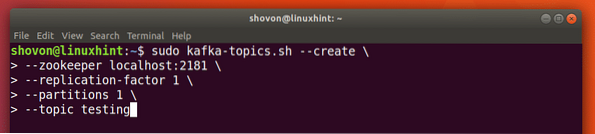
Lag nytt Kafka-emne
Et testemne vil bli opprettet som vi kan bekrefte med den nevnte kommandoen:
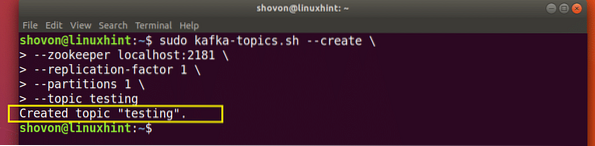
Kafka Emneopprettelsesbekreftelse
Skrive meldinger på et emne
Som vi studerte tidligere, er en av API-ene som er til stede i Apache Kafka Produsent-API. Vi bruker denne API-en til å lage en ny melding og publisere til emnet vi nettopp opprettet:
Skrive melding til emnet
sudo kafka-konsoll-produsent.sh - meglerliste localhost: 9092 - emnetestingLa oss se utdataene for denne kommandoen:
Publiser melding til Kafka Topic
Når vi trykker på tasten, vil vi se et nytt piltegn (>) som betyr at vi kan gå ut av data nå:

Skrive en melding
Bare skriv inn noe og trykk for å starte en ny linje. Jeg skrev inn 3 tekstlinjer:
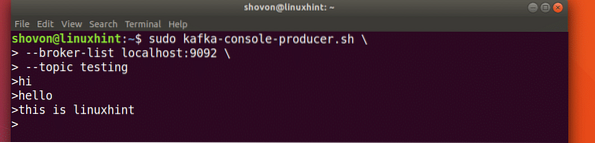
Lese meldinger fra emnet
Nå som vi har publisert en melding om Kafka-emnet vi opprettet, vil denne meldingen være der i noen konfigurerbar tid. Vi kan lese den nå ved hjelp av Forbruker-API:
Lese meldinger fra emnet
sudo kafka-konsoll-forbruker.sh --zookeeper lokal vert: 2181 --emnetesting - fra begynnelsen
Her er hva vi kommer tilbake med denne kommandoen:
Kommando om å lese Melding fra Kafka Topic
Vi vil kunne se meldingene eller linjene vi har skrevet ved hjelp av Producer API som vist nedenfor:
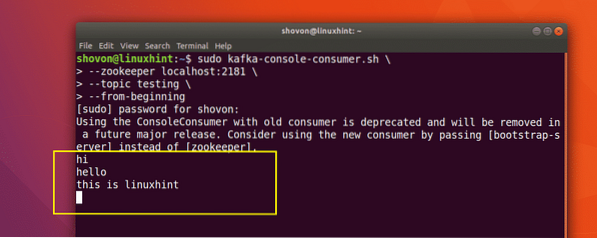
Hvis vi skriver en ny ny melding ved hjelp av Producer API, vil den også vises øyeblikkelig på forbrukersiden:
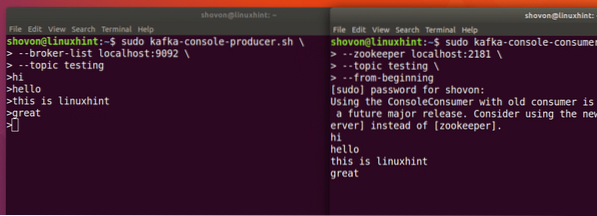
Publiser og forbruk samtidig
Konklusjon
I denne leksjonen så vi på hvordan vi begynner å bruke Apache Kafka, som er en utmerket meldingsmegler og også kan fungere som en spesiell dataprestensjonsenhet.


