Big data er data i rekkefølgen av terabyte eller petabyte og utover, bestående av gruvedrift, analyse og prediktiv modellering av store datasett. Den raske veksten av informasjon og teknologisk utvikling har gitt en unik mulighet for enkeltpersoner og bedrifter over hele verden til å oppnå fortjeneste og utvikle nye evner som omdefinerer tradisjonelle forretningsmodeller ved hjelp av analyser i stor skala.
Denne artikkelen gir et fugleperspektiv på fem av de mest populære open source dataplattformene. Her er listen vår:
Apache Hadoop
Apache Hadoop er en åpen kildekode programvareplattform som behandler veldig store datasett i et distribuert miljø med hensyn til lagring og beregningskraft, og er hovedsakelig bygget på lavprisvarevare.
Apache Hadoop er designet for å enkelt skalere opp fra noen få til tusenvis av servere. Det hjelper deg å behandle lokalt lagrede data i et generelt parallelt behandlingsoppsett. En av fordelene med Hadoop er at den håndterer feil på programvarenivå. Følgende figur illustrerer den overordnede arkitekturen til Hadoop-økosystemet og hvor de forskjellige rammene er innenfor det:
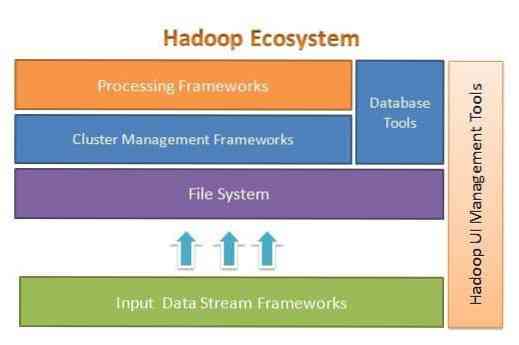
Apache Hadoop gir et rammeverk for filsystemlaget, klyngebehandlingslaget og behandlingslaget. Det etterlater et alternativ for andre prosjekter og rammer å komme og jobbe sammen med Hadoop Ecosystem og utvikle sine egne rammer for noen av lagene som er tilgjengelige i systemet.
Apache Hadoop består av fire hovedmoduler. Disse modulene er Hadoop Distributed File System (filsystemlaget), Hadoop MapReduce (som fungerer både med klyngeadministrasjon og behandlingslaget), Yet Another Resource Negotiator (YARN, klyngestyringslaget) og Hadoop Common.
Elasticsearch
Elasticsearch er en fulltekstbasert søke- og analysemotor. Det er et svært skalerbart og distribuert system, spesielt designet for å jobbe effektivt og raskt med store datasystemer, der en av de viktigste brukssakene er logganalyse. Den er i stand til å utføre avanserte og komplekse søk, og nesten sanntidsbehandling for avansert analyse og operativ intelligens.
Elasticsearch er skrevet på Java og er basert på Apache Lucene. Utgitt i 2010, og det ble raskt populært på grunn av sin fleksible datastruktur, skalerbare arkitektur og veldig rask responstid. Elasticsearch er basert på et JSON-dokument med en skjemafri struktur, noe som gjør adopsjon enkel og problemfri. Det er en av de topprangerte søkemotorene av bedriftsgrad. Du kan skrive klienten på et hvilket som helst programmeringsspråk. Elasticsearch jobber offisielt med Java, .NET, PHP, Python, Perl og så videre.
Elasticsearch samhandler hovedsakelig ved hjelp av et REST API. Den får data i form av JSON-dokumenter med alle nødvendige parametere, og gir svaret på en lignende måte.
MongoDB
MongoDB er en NoSQL-database basert på dokumentlagermodellen. I MongoDB er alt enten samling eller dokument. For å forstå MongoDB-terminologi er samling et alternativt ord for tabell, mens dokument er et alternativt ord for rader.
MongoDB er en åpen kildekode, dokumentorientert og plattformbasert database. Det er først og fremst skrevet i C++. Det er også den ledende NoSQL-databasen som gir høy ytelse, høy tilgjengelighet og enkel skalerbarhet. MongoDB bruker JSON-lignende dokumenter med skjema og gir en rik spørrestøtte. Noen av de viktigste funksjonene inkluderer indeksering, replikering, lastbalansering, aggregering og lagring av filer.
Cassandra
Cassandra er et åpen kildekode Apache-prosjekt designet for NoSQL-databaseadministrasjon. Cassandra-rader er organisert i tabeller og indeksert av en nøkkel. Den bruker en bare loggbasert lagringsmotor. Data i Cassandra fordeles over flere masterløse noder, uten et eneste feilpunkt. Det er et topp-nivå Apache-prosjekt, og utviklingen er for tiden overvåket av Apache Software Foundation (ASF).
Cassandra er designet for å løse problemer knyttet til drift i stor skala (web). Gitt Cassandras mesterløse arkitektur, er den i stand til å fortsette å utføre operasjoner til tross for et lite (om enn betydelig) antall maskinvarefeil. Cassandra kjører på tvers av flere noder på tvers av flere datasentre. Den replikerer data på tvers av disse datasentrene for å unngå feil eller nedetid. Dette gjør det til et veldig feiltolerant system.
Cassandra bruker sitt eget programmeringsspråk for å få tilgang til data på tvers av nodene. Det kalles Cassandra Query Language eller CQL. Det ligner på SQL, som hovedsakelig brukes av Relational Databases. CQL kan brukes ved å kjøre sin egen applikasjon kalt cqlsh. Cassandra gir også mange integrasjonsgrensesnitt for flere programmeringsspråk for å bygge en applikasjon ved hjelp av Cassandra. Integrasjons-API-et støtter Java, C ++, Python og andre.
Apache HBase
HBase er et annet Apache-prosjekt designet for å administrere NoSQL-datalageret. Den er designet for å benytte Hadoop Ecosystems funksjoner, inkludert pålitelighet, feiltoleranse og så videre. Den bruker HDFS som et filsystem for lagringsformål. Det er flere datamodeller som NoSQL jobber med, og Apache HBase tilhører den kolonneorienterte datamodellen. HBase var opprinnelig basert på Google Big Table, som også er relatert til den kolonneorienterte modellen for ustrukturerte data.
HBase lagrer alt i form av et nøkkelverdipar. Det viktige å merke seg er at i HBase er en nøkkel og en verdi i form av byte. Så for å lagre all informasjon i HBase, må du konvertere informasjon til byte. (Med andre ord godtar API-en ikke noe annet enn byte-array.) Vær forsiktig med HBase, som når du lagrer data, bør du huske den opprinnelige typen. Data som opprinnelig var en streng, returneres som en byte-array hvis de ikke blir husket feil. Som et resultat vil det opprette en feil i applikasjonen din og krasjer applikasjonen din.
Håper du likte denne artikkelen. Hvis du ønsker å arkitektere og designe datakrevende applikasjoner, kan du utforske Anuj Kumars Arkitektur Data-intensive applikasjoner. Dette bok er inngangsporten din til å bygge smarte datakrevende systemer ved å innlemme de kjerne datakrevende arkitektoniske prinsippene, mønstrene og teknikkene direkte i applikasjonsarkitekturen din.


