I denne leksjonen om maskinlæring med scikit-læring vil vi lære forskjellige aspekter av denne utmerkede Python-pakken som lar oss bruke enkle og komplekse maskinlæringsegenskaper på et variert sett med data sammen med funksjonalitet for å teste hypotesen vi etablerer.
Scikit-lære-pakken inneholder enkle og effektive verktøy for å anvende data mining og dataanalyse på datasett, og disse algoritmene er tilgjengelige for bruk i forskjellige sammenhenger. Det er en åpen kildekode-pakke tilgjengelig under en BSD-lisens, noe som betyr at vi kan bruke dette biblioteket til og med kommersielt. Den er bygget på toppen av matplotlib, NumPy og SciPy, så den er allsidig i naturen. Vi vil bruke Anaconda med Jupyter-notatbok for å presentere eksempler i denne leksjonen.
Hva scikit-learning gir?
Scikit-learning-biblioteket fokuserer fullstendig på datamodellering. Vær oppmerksom på at det ikke er noen store funksjoner til stede i scikit-læringen når det gjelder lasting, manipulering og oppsummering av data. Her er noen av de populære modellene som scikit-learning gir oss:
- Gruppering for å gruppere merkede data
- Datasett å gi testdatasett og undersøke modellatferd
- Kryssvalidering å estimere ytelsen til overvåkede modeller på usynlige data
- Ensemblemetoder for å kombinere spådommer fra flere modeller under tilsyn
- Funksjonsekstraksjon til å definere attributter i bilde- og tekstdata
Installer Python scikit-learning
Bare et notat før vi starter installasjonsprosessen, bruker vi et virtuelt miljø for denne leksjonen som vi laget med følgende kommando:
python -m virtualenv scikitkilde scikit / bin / aktiver
Når det virtuelle miljøet er aktivt, kan vi installere pandabiblioteket i det virtuelle miljøet slik at eksempler vi oppretter neste kan utføres:
pip install scikit-lærEller vi kan bruke Conda til å installere denne pakken med følgende kommando:
conda installer scikit-lærVi ser noe slikt når vi utfører kommandoen ovenfor:

Når installasjonen er fullført med Conda, vil vi kunne bruke pakken i våre Python-skript som:
importere sklearnLa oss begynne å bruke scikit-learning i våre skript for å utvikle fantastiske maskinlæringsalgoritmer.
Importerer datasett
Noe av det kule med scikit-learning er at det kommer forhåndslastet med eksempeldatasett som det er lett å komme raskt i gang med. Datasettene er iris og sifre datasett for klassifisering og boston huspriser datasett for regresjonsteknikker. I denne delen vil vi se på hvordan du laster inn og begynner å bruke iris-datasettet.
For å importere et datasett, må vi først importere riktig modul etterfulgt av å få hold til datasettet:
fra sklearn import datasettiris = datasett.load_iris ()
sifre = datasett.lastesifre ()
sifre.data
Når vi kjører kodebiten ovenfor, ser vi følgende utdata:

Hele utgangen fjernes for kortfattethet. Dette er datasettet vi hovedsakelig bruker i denne leksjonen, men de fleste konseptene kan brukes på generelt sett alle datasettene.
Bare et morsomt faktum å vite at det er flere moduler tilstede i scikit økosystem, hvorav den ene er lære brukes til maskinlæringsalgoritmer. Se denne siden for mange andre moduler til stede.
Utforske datasettet
Nå som vi har importert det medfølgende sifredatasettet til skriptet vårt, bør vi begynne å samle grunnleggende informasjon om datasettet, og det er det vi vil gjøre her. Her er de grunnleggende tingene du bør utforske mens du leter etter informasjon om et datasett:
- Målverdiene eller etikettene
- Beskrivelsesattributtet
- Nøklene som er tilgjengelige i det gitte datasettet
La oss skrive en kort kodebit for å trekke ut de tre ovennevnte informasjonene fra datasettet vårt:
print ('Target:', sifre.mål)print ('Keys:', sifre.nøkler ())
print ('Beskrivelse:', sifre.BESKRIVELSE
Når vi kjører kodebiten ovenfor, ser vi følgende utdata:
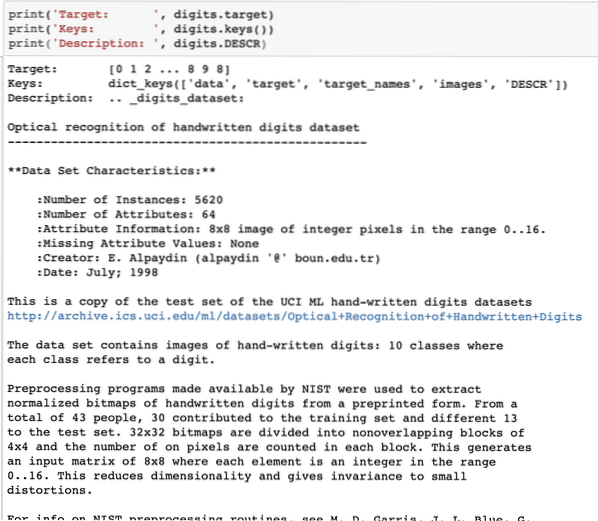
Vær oppmerksom på at de variable sifrene ikke er greie. Da vi skrev ut sifret datasettet, inneholdt det faktisk numpy arrays. Vi får se hvordan vi får tilgang til disse matriser. Legg merke til tastene som er tilgjengelige i sifreinstansen vi skrev ut i den siste kodebiten.
Vi begynner med å få formen til matrisedataene, som er radene og kolonnene som matrisen har. For dette må vi først få de faktiske dataene og deretter få formen:
sifre_sett = sifre.dataskriv ut (sifersett.form)
Når vi kjører kodebiten ovenfor, ser vi følgende utdata:

Dette betyr at vi har 1797 prøver i datasettet vårt sammen med 64 datafunksjoner (eller kolonner). Vi har også noen målmerker som vi vil visualisere her ved hjelp av matplotlib. Her er et kodebit som hjelper oss å gjøre det:
importer matplotlib.pyplot som plt# Slå sammen bildene og måletikettene som en liste
images_and_labels = liste (zip (sifre.bilder, sifre.mål))
for indeks, (image, label) i enumerate (images_and_labels [: 8]):
# initialiser en delplott på 2X4 i i + 1-posisjon
plt.delplott (2, 4, indeks + 1)
# Ingen grunn til å plotte noen akser
plt.akse ('av')
# Vis bilder i alle delplottene
plt.imshow (bilde, cmap = plt.cm.grå_r, interpolasjon = 'nærmeste')
# Legg til en tittel til hver delplott
plt.tittel ('Trening:' + str (etikett))
plt.vise fram()
Når vi kjører kodebiten ovenfor, ser vi følgende utdata:

Legg merke til hvordan vi glidelå de to NumPy-matrikkene sammen før vi plottet dem på et 4 av 2 rutenett uten akseinformasjon. Nå er vi sikre på informasjonen vi har om datasettet vi jobber med.
Nå som vi vet at vi har 64 datafunksjoner (som for øvrig er mange funksjoner), er det utfordrende å visualisere de faktiske dataene. Vi har en løsning på dette skjønt.
Hovedkomponentanalyse (PCA)
Dette er ikke en veiledning om PCA, men la oss gi en liten ide om hva det er. Siden vi vet at for å redusere antall funksjoner fra et datasett, har vi to teknikker:
- Eliminering av funksjoner
- Funksjonsekstraksjon
Mens den første teknikken står overfor problemet med tapte datafunksjoner, selv når de kan ha vært viktige, lider den andre teknikken ikke av problemet som ved hjelp av PCA, vi konstruerer nye datafunksjoner (mindre i antall) der vi kombinerer legge inn variabler på en slik måte at vi kan utelate de "minst viktige" variablene mens vi fortsatt beholder de mest verdifulle delene av alle variablene.
Som forventet, PCA hjelper oss med å redusere høydimensjonaliteten til data som er et direkte resultat av å beskrive et objekt ved hjelp av mange datafunksjoner. Ikke bare sifre, men mange andre praktiske datasett har mange funksjoner som inkluderer finansinstitusjonsdata, vær- og økonomidata for en region osv. Når vi utfører PCA på sifret datasettet, vårt mål vil være å finne bare to funksjoner slik at de har de fleste egenskapene av datasettet.
La oss skrive en enkel kodebit for å bruke PCA på sifret datasettet for å få vår lineære modell med bare to funksjoner:
fra sklearn.nedbrytingsimport PCAfeature_pca = PCA (n_components = 2)
redusert_data_random = funksjon_pca.fit_transform (sifre.data)
modell_pca = PCA (n_komponenter = 2)
redusert_data_pca = modell_pca.fit_transform (sifre.data)
redusert_data_pca.form
skriv ut (redusert_data_ tilfeldig)
skriv ut (redusert_data_pca)
Når vi kjører kodebiten ovenfor, ser vi følgende utdata:
[[ -1.2594655 21.27488324][7.95762224 -20.76873116]
[6.99192123 -9.95598191]
..
[10.8012644 -6.96019661]
[-4.87210598 12.42397516]
[-0.34441647 6.36562581]]
[[ -1.25946526 21.27487934]
[7.95761543 -20.76870705]
[6.99191947 -9.9559785]
..
[10.80128422 -6.96025542]
[-4.87210144 12.42396098]
[-0.3443928 6.36555416]]
I koden ovenfor nevner vi at vi bare trenger to funksjoner for datasettet.
Nå som vi har god kunnskap om datasettet vårt, kan vi bestemme hva slags maskinlæringsalgoritmer vi kan bruke på det. Kunnskap om et datasett er viktig fordi det er slik vi kan bestemme hvilken informasjon som kan hentes ut av det og med hvilke algoritmer. Det hjelper oss også å teste hypotesen vi etablerer mens vi forutsier fremtidige verdier.
Å bruke k-betyr klynging
K-betyr klyngealgoritmen er en av de enkleste klyngealgoritmene for læring uten tilsyn. I denne klyngingen har vi noe tilfeldig antall klynger, og vi klassifiserer datapunktene våre i en av disse klyngene. K-betyr-algoritmen vil finne nærmeste klynge for hvert av det gitte datapunktet og tilordne datapunktet til den klyngen.
Når klyngingen er ferdig, beregnes sentrum av klyngen på nytt, datapunktene tildeles nye klynger hvis det er noen endringer. Denne prosessen gjentas til datapunktene slutter å endres der klynger for å oppnå stabilitet.
La oss ganske enkelt bruke denne algoritmen uten forbehandling av dataene. For denne strategien vil kodebiten være ganske enkel:
fra sklearn importklyngenk = 3
k_means = klynge.KM betyr (k)
# fit data
k_means.passform (sifre.data)
# utskriftsresultater
skriv ut (k_means.etiketter _ [:: 10])
skriv ut (sifre.mål [:: 10])
Når vi kjører kodebiten ovenfor, ser vi følgende utdata:
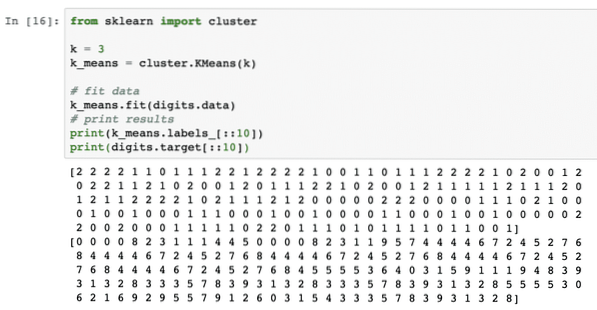
I ovennevnte utgang kan vi se forskjellige klynger til hvert av datapunktet.
Konklusjon
I denne leksjonen så vi på et utmerket maskinlæringsbibliotek, scikit-learning. Vi lærte at det er mange andre moduler tilgjengelig i scikit-familien, og vi brukte enkel k-betyr-algoritme på det angitte datasettet. Det er mange flere algoritmer som kan brukes på datasettet bortsett fra k-betyr klynging som vi brukte i denne leksjonen, vi oppfordrer deg til å gjøre det og dele resultatene dine.
Del din tilbakemelding på leksjonen på Twitter med @sbmaggarwal og @LinuxHint.


