- 1 for sann eller
- 0 for falsk
Nøkkelen til logistisk regresjon:
- De uavhengige variablene må ikke være multikollinearitet; hvis det er noe forhold, så bør det være veldig lite.
- Datasettet for logistisk regresjon bør være stort nok til å få bedre resultater.
- Bare disse attributtene skal være der i datasettet, som har noen betydning.
- De uavhengige variablene må være i henhold til loggodds.
Å bygge modellen til logistisk regresjon, vi bruker scikit-lær bibliotek. Prosessen med den logistiske regresjonen i python er gitt nedenfor:
- Importer alle nødvendige pakker for logistisk regresjon og andre biblioteker.
- Last opp datasettet.
- Forstå de uavhengige datasettvariablene og avhengige variablene.
- Del datasettet i opplærings- og testdata.
- Initialiser den logistiske regresjonsmodellen.
- Tilpass modellen med treningsdatasettet.
- Forutsi modellen ved hjelp av testdataene og beregn nøyaktigheten til modellen.
Problem: De første trinnene er å samle inn datasettet som vi vil bruke Logistisk regresjon. Datasettet som vi skal bruke her er for MS opptaksdatasett. Dette datasettet har fire variabler og hvorav tre er uavhengige variabler (GRE, GPA, work_experience), og en er en avhengig variabel (innrømmet). Dette datasettet vil fortelle om kandidaten vil få opptak til et prestisjefylt universitet eller ikke basert på GPA, GRE eller arbeidsopplevelse.
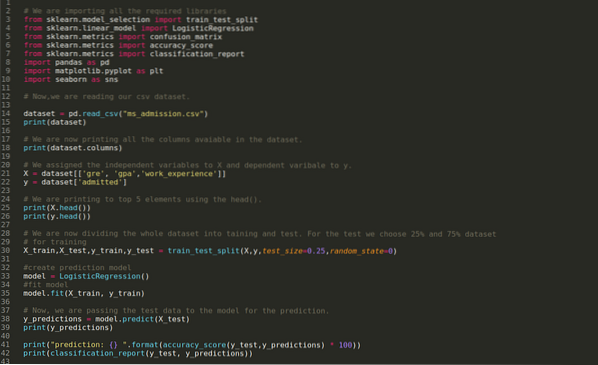
Trinn 1: Vi importerer alle nødvendige biblioteker som vi krevde for python-programmet.
Steg 2: Nå laster vi inn ms-opptaksdatasettet ved hjelp av read_csv-pandafunksjonen.

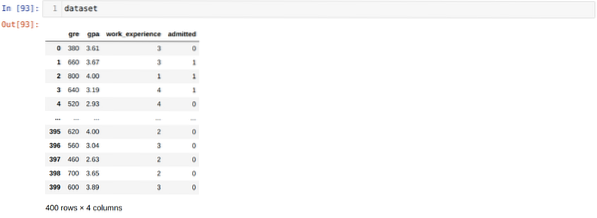
Trinn 3: Datasettet ser ut som nedenfor:
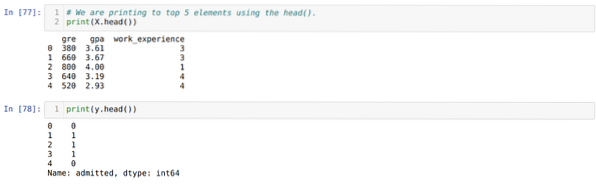
Trinn 4: Vi sjekker alle kolonnene som er tilgjengelige i datasettet, og setter deretter alle uavhengige variabler til variabel X og avhengige variabler til y, som vist i skjermbildet nedenfor.

Trinn 5: Etter å ha satt de uavhengige variablene til X og den avhengige variabelen til y, skriver vi nå ut her for å kryssjekke X og y ved hjelp av hodepandafunksjonen.
Trinn 6: Nå skal vi dele hele datasettet i opplæring og test. For dette bruker vi train_test_split-metoden til sklearn. Vi har gitt 25% av hele datasettet til testen og de resterende 75% av datasettet til treningen.
Trinn 7: Nå skal vi dele hele datasettet i opplæring og test. For dette bruker vi metoden train_test_split for sklearn. Vi har gitt 25% av hele datasettet til testen og de resterende 75% av datasettet til treningen.
Deretter lager vi Logistic Regression-modellen og passer til treningsdataene.
Trinn 8: Nå er modellen vår klar for prediksjon, så vi sender nå testdataene (X_test) til modellen og fikk resultatene. Resultatene viser (y_forutsigelser) at verdiene 1 (innrømmet) og 0 (ikke tillatt).

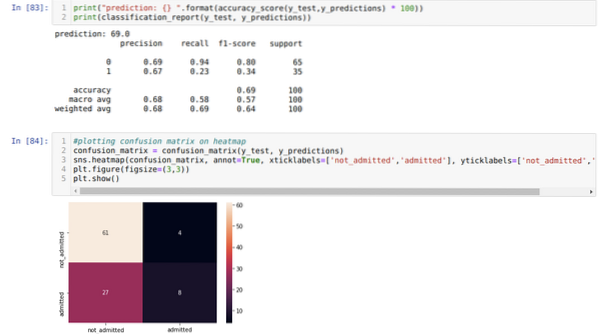
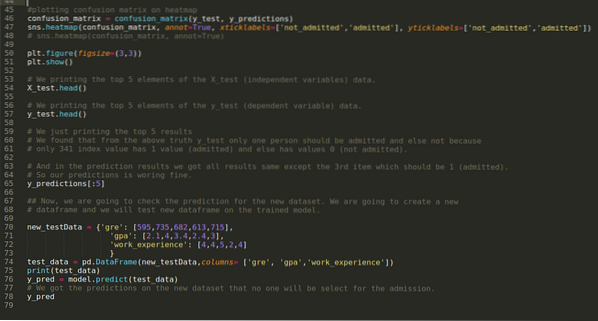
Trinn 9: Nå skriver vi ut klassifiseringsrapporten og forvirringsmatrisen.
Klassifiseringsrapporten viser at modellen kan forutsi resultatene med en nøyaktighet på 69%.
Forvirringsmatrisen viser de totale X_test-datadetaljene som:
TP = ekte positive = 8
TN = ekte negative = 61
FP = falske positive = 4
FN = falske negative = 27
Så den totale nøyaktigheten i henhold til confusion_matrix er:
Nøyaktighet = (TP + TN) / Total = (8 + 61) / 100 = 0.69
Trinn 10: Nå skal vi kryssjekke resultatet gjennom utskrift. Så vi skriver bare ut de 5 beste elementene i X_test og y_test (faktisk sann verdi) ved hjelp av hodepandafunksjonen. Deretter skriver vi også ut de 5 beste resultatene av spådommene som vist nedenfor:
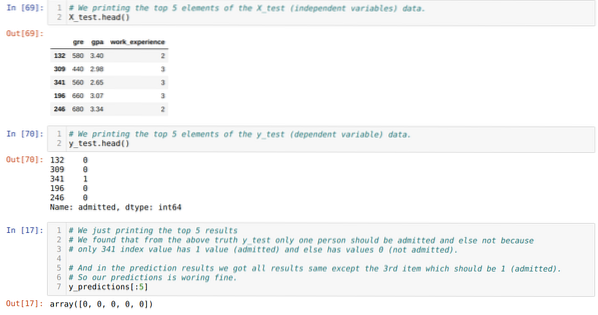
Vi kombinerer alle tre resultatene i et ark for å forstå spådommene som vist nedenfor. Vi kan se at bortsett fra 341 X_test-dataene, som var sanne (1), er prediksjonen falsk (0) annet. Så modellforutsigelsene våre fungerer 69%, som vi allerede har vist ovenfor.

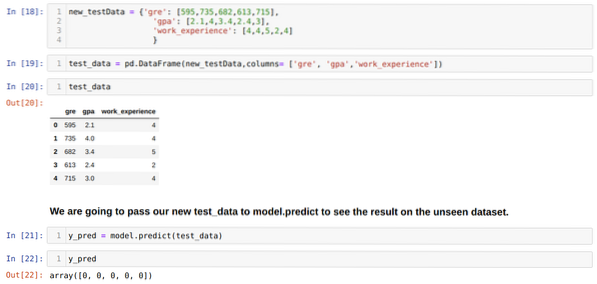
Trinn 11: Så vi forstår hvordan modellforutsigelsene gjøres på det usett datasettet som X_test. Så vi opprettet bare et tilfeldig nytt datasett ved hjelp av en pandas dataframe, sendte det til den trente modellen og fikk resultatet vist nedenfor.
Den komplette koden i python gitt nedenfor:
Koden for denne bloggen, sammen med datasettet, er tilgjengelig på følgende lenke
https: // github.com / shekharpandey89 / logistisk-regresjon


