Før du bruker pandas pivottabell, må du sørge for at du forstår dataene og spørsmålene du prøver å løse gjennom pivottabellen. Ved å bruke denne metoden kan du gi kraftige resultater. Vi vil utdype i denne artikkelen hvordan du lager en pivottabell i pandas python.
Les data fra Excel-fil
Vi har lastet ned en Excel-database med salg av mat. Før du starter implementeringen, må du installere noen nødvendige pakker for å lese og skrive Excel-databasefilene. Skriv inn følgende kommando i terminaldelen av pycharm-redigereren:
pip installer xlwt openpyxl xlsxwriter xlrd
Les nå data fra excel-arket. Importer de nødvendige pandabibliotekene og endre banen til databasen din. Ved å kjøre følgende kode, kan data hentes fra filen.
importer pandaer som pdimporter nummen som np
dtfrm = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
skrive ut (dtfrm)
Her blir dataene lest fra excel-databasen over matvarer og overført til dataframe-variabelen.
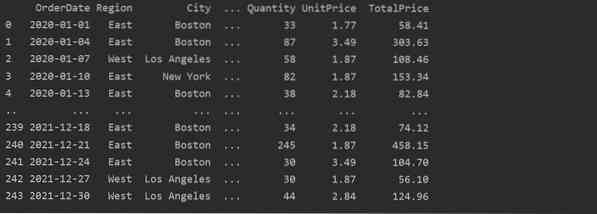
Lag pivottabell ved hjelp av Pandas Python
Nedenfor har vi laget en enkel pivottabell ved å bruke matsalgsdatabasen. To parametere kreves for å lage en pivottabell. Den første er data som vi har overført til datarammen, og den andre er en indeks.
Pivotdata på en indeks
Indeksen er funksjonen i en pivottabell som lar deg gruppere dataene dine basert på krav. Her har vi tatt 'Produkt' som indeks for å lage en grunnleggende pivottabell.
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataramme, indeks = ["Produkt"])
skriv ut (pivot_tble)
Følgende resultat vises etter kjøring av kildekoden ovenfor:
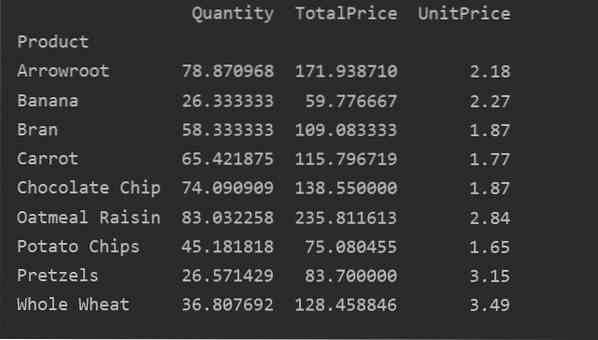
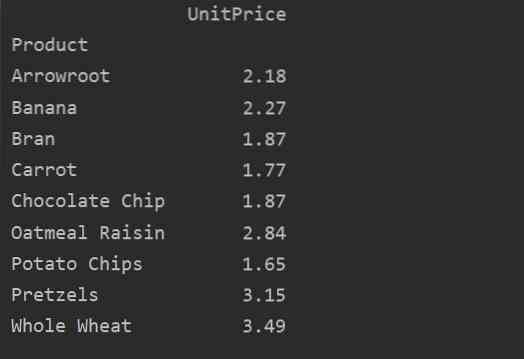
Definere kolonner eksplisitt
For mer analyse av dataene dine, definer du eksplisitt kolonnenavnene med indeksen. For eksempel ønsker vi å vise den eneste UnitPrice for hvert produkt i resultatet. For dette formålet, legg til verdiparameteren i pivottabellen. Følgende kode gir deg det samme resultatet:
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataframe, index = 'Product', values = 'UnitPrice')
skriv ut (pivot_tble)
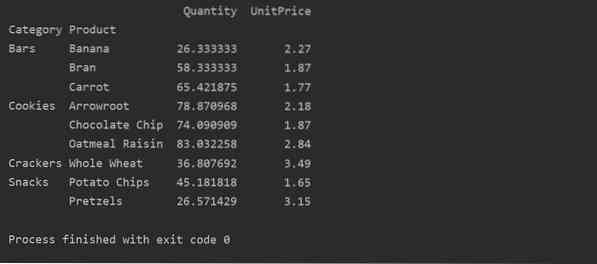
Pivotdata med multiindeks
Data kan grupperes basert på mer enn én funksjon som en indeks. Ved å bruke flerindekstilnærmingen kan du få mer spesifikke resultater for dataanalyse. For eksempel kommer produkter under forskjellige kategorier. Så du kan vise indeksen 'Produkt' og 'Kategori' med tilgjengelig 'Mengde' og 'Enhetspris' for hvert produkt som følger:
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataramme, indeks = ["Kategori", "Produkt"], verdier = ["Enhetspris", "Mengde"])
skriv ut (pivot_tble)
Bruke aggregeringsfunksjon i pivottabellen
I en pivottabell kan aggfunc brukes for forskjellige funksjonsverdier. Den resulterende tabellen er en oppsummering av funksjonsdata. Den samlede funksjonen gjelder gruppedataene dine i pivottabell. Som standard er samlet funksjon np.mener(). Men basert på brukerkrav kan forskjellige samlede funksjoner gjelde for forskjellige datafunksjoner.
Eksempel:
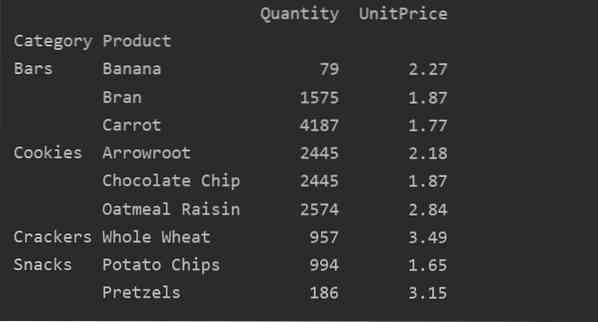
Vi har brukt samlede funksjoner i dette eksemplet. Np.sum () -funksjonen brukes til funksjonen 'Mengde' og np.middel () -funksjon for 'UnitPrice' -funksjon.
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataramme, indeks = ["Kategori", "Produkt"], aggfunc = 'Mengde': np.sum, 'UnitPrice': np.mener)
skriv ut (pivot_tble)
Etter å ha brukt aggregeringsfunksjonen for forskjellige funksjoner, får du følgende utdata:
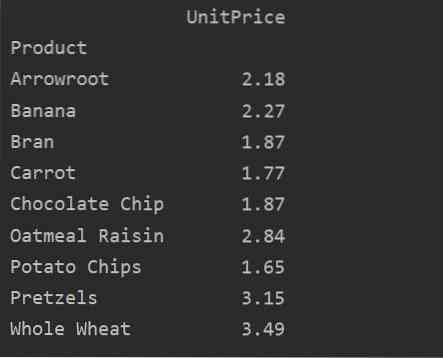
Ved hjelp av verdiparameteren kan du også bruke aggregatfunksjon for en bestemt funksjon. Hvis du ikke vil spesifisere funksjonens verdi, samler den databasens numeriske funksjoner. Ved å følge den gitte kildekoden kan du bruke den samlede funksjonen for en bestemt funksjon:
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataramme, indeks = ['Produkt'], verdier = ['Enhetspris'], aggfunc = np.mener)
skriv ut (pivot_tble)
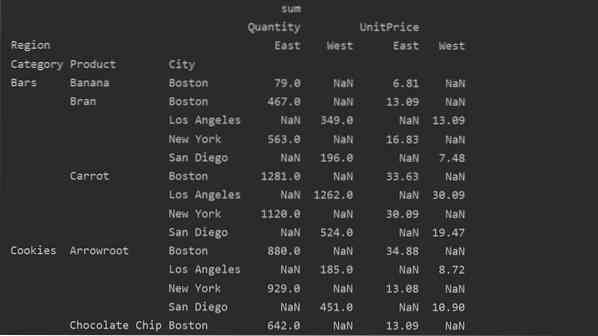
Forskjell mellom verdier vs. Kolonner i pivottabellen
Verdiene og kolonnene er det viktigste forvirrende punktet i pivottabellen. Det er viktig å merke seg at kolonner er valgfrie felt, som viser den resulterende tabellens verdier horisontalt på toppen. Aggregeringsfunksjonen aggfunc gjelder verdifeltet du lister opp.
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataramme, indeks = ['Kategori', 'Produkt', 'By'], verdier = ['Enhetspris', 'Antall'],
kolonner = ['Region'], aggfunc = [np.sum])
skriv ut (pivot_tble)
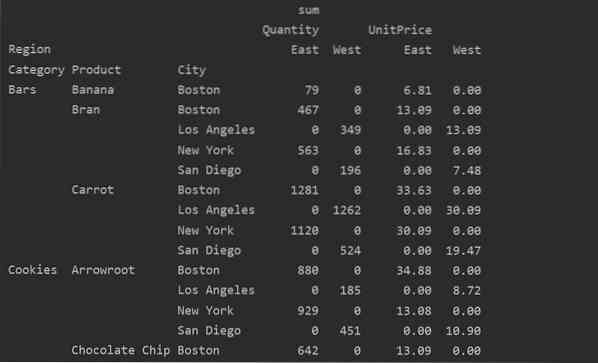
Håndtering av manglende data i pivottabellen
Du kan også håndtere de manglende verdiene i pivottabellen ved å bruke 'fill_value' Parameter. Dette lar deg erstatte NaN-verdiene med en ny verdi som du gir for å fylle ut.
For eksempel fjernet vi alle nullverdier fra tabellen ovenfor ved å kjøre følgende kode og erstatter NaN-verdiene med 0 i hele den resulterende tabellen.
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataramme, indeks = ['Kategori', 'Produkt', 'By'], verdier = ['Enhetspris', 'Antall'],
kolonner = ['Region'], aggfunc = [np.sum], fill_value = 0)
skriv ut (pivot_tble)
Filtrering i pivottabell
Når resultatet er generert, kan du bruke filteret ved å bruke standard dataframe-funksjonen. La oss ta et eksempel. Filtrer produktene hvis UnitPrice er mindre enn 60. Den viser produktene med en pris på under 60.
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivottabell (dataframe, index = 'Product', values = 'UnitPrice', aggfunc = 'sum')
low_price = pivot_tble [pivot_tble ['UnitPrice'] < 60]
skriv ut (lav pris)

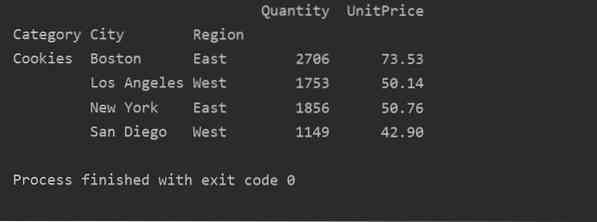
Ved å bruke en annen spørringsmetode kan du filtrere resultatene. For eksempel har vi for eksempel filtrert informasjonskapselkategorien basert på følgende funksjoner:
importer pandaer som pdimporter nummen som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivottabell (dataramme, indeks = ["Kategori", "By", "Region"], verdier = ["Enhetspris", "Antall"], aggfunc = np.sum)
pt = pivot_tble.spørring ('Category == ["Cookies"]')
skrive ut (pt)
Produksjon:
Visualiser pivottabelldataene
Følg følgende metode for å visualisere pivottabelldataene:
importer pandaer som pdimporter nummen som np
importer matplotlib.pyplot som plt
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivottabell (dataramme, indeks = ["Kategori", "Produkt"], verdier = ["Enhetspris"])
pivot_tble.tomt (kind = 'bar');
plt.vise fram()
I visualiseringen ovenfor har vi vist enhetsprisen på de forskjellige produktene sammen med kategorier.

Konklusjon
Vi undersøkte hvordan du kan generere en pivottabell fra datarammen ved hjelp av Pandas python. En pivottabell lar deg generere dyp innsikt i datasettene dine. Vi har sett hvordan vi kan generere en enkel pivottabell ved hjelp av multiindeks og bruke filtrene på pivottabeller. Videre har vi også vist å plotte pivottabeldata og fylle manglende data.


